



TABLE OF CONTENTS
GitOps Beyond ArgoCD: Patterns That Scale for Large Engineering Organisations

ArgoCD became the default answer when someone said “GitOps” for a good few years. It solved the most common problem neatly: sync your Kubernetes cluster state to what is defined in a Git repository. For teams running a handful of clusters with manageable application counts, ArgoCD works extremely well. The friction begins when the organisation grows.
When you are running dozens of clusters across regions, when multiple teams own different parts of the deployment estate, and when your delivery velocity means hundreds of changes moving through the system daily, the assumptions baked into a single ArgoCD installation start to show their limits. This guide covers the patterns that engineering organisations at scale are using to move GitOps beyond a single tool.
Where ArgoCD Begins to Show Strain
ArgoCD’s architecture is fundamentally a controller that reconciles desired state in Git with observed state in Kubernetes. That reconciliation loop is elegant, but it runs against the resources it manages. At scale, this means the application controller CPU and memory consumption grows with the number of Application objects being managed.
Teams running large estates typically encounter a few recurring friction points:
- Application sprawl: thousands of ArgoCD Application objects in a single control plane instance creates observable latency in sync operations
- Cross-cluster consistency: keeping the same configuration standard across clusters in different cloud accounts or regions without duplication
- Team autonomy vs platform governance: developers need enough access to troubleshoot their deployments without being able to affect other teams’ workloads
- Audit and drift detection at scale: knowing which clusters have drifted from their declared state across a large fleet
None of these are unsolvable in ArgoCD. They are, however, solved differently at scale than they are in a small installation. Understanding the patterns available is what separates teams that grow cleanly from those that accumulate operational debt.
Scaling your GitOps setup
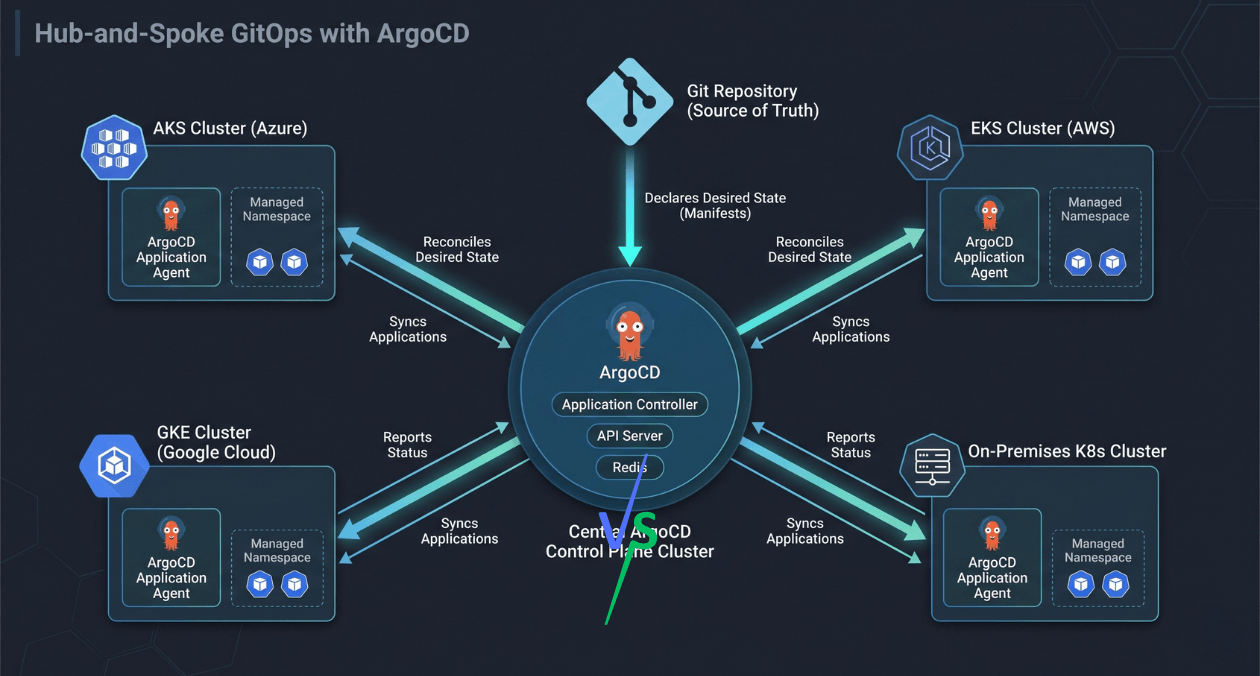
Pattern 1: Hub and Spoke with ArgoCD
The most common scaling pattern for teams already invested in ArgoCD is the hub-and-spoke model. A central management cluster runs the ArgoCD control plane. The managed clusters are registered as targets and do not run ArgoCD themselves. The hub controller manages synchronisation across all spokes.
This pattern significantly reduces the operational overhead of maintaining ArgoCD across many clusters. Upgrades, RBAC policies, and ApplicationSet templates all live in one place. The hub can apply consistent policies across the fleet without each cluster team needing to manage their own controller.
The limitation is availability coupling. If the hub cluster has an issue, sync operations across all spoke clusters are affected. Teams at very high scale often run a small number of regional hub clusters rather than a single global one, trading some management simplicity for resilience.
Pattern 2: Flux as an Alternative or Complement
Flux is ArgoCD’s closest architectural sibling in the GitOps space. It also follows the pull-based reconciliation model, but it is structured differently. Where ArgoCD is a unified application, Flux is a set of composable controllers that each handle a specific concern: source synchronisation, Kustomize reconciliation, Helm release management, and notifications.
For large organisations, Flux’s composability is its main advantage. Teams can adopt only the controllers relevant to their workflow and build a platform that reflects how they actually work rather than how the tool assumes they work.
| Dimension | ArgoCD | Flux |
| Architecture | Monolithic application controller | Composable controller set |
| UI | Rich built-in dashboard | CLI-first, optional UI via Weave GitOps |
| Multi-cluster | Hub-and-spoke pattern | Fleet and tenant model |
Some organisations run both. ArgoCD handles application delivery where teams want a UI-centric workflow and pull request previews. Flux handles infrastructure and platform components where composability and tight Helm operator integration matter more. This is not an anti-pattern at scale. It is a pragmatic recognition that different workloads have different delivery requirements.
Pattern 3: ApplicationSets for Fleet-Wide Templating
For teams committed to ArgoCD but needing to manage large numbers of similar applications across many clusters, ApplicationSet is the feature that changes the calculus. ApplicationSet allows you to template ArgoCD Application objects and generate them programmatically based on data sources.
A cluster generator can create an Application for every registered cluster automatically. A Git generator can create an Application for every directory in a monorepo. A matrix generator can combine both to create an Application for every service on every cluster. This removes the manual work of creating and maintaining Application objects at scale
- Cluster generator: create one Application per registered cluster in your fleet
- Git generator: create Applications based on directory or file structure in a repository
- Pull request generator: create ephemeral Applications for each open PR for preview environments
- Matrix generator: combine two or more generators to create the cross-product of Applications
Scaling your GitOps setup
Pattern 4: GitOps for Platform Engineering Teams
Platform engineering teams have a different relationship with GitOps than application teams. Where application teams use GitOps to deploy their service, platform teams use it to manage the shared infrastructure that application teams depend on: cluster add-ons, service meshes, policy controllers, monitoring stacks.
The challenge is that platform components often have ordering dependencies that declarative synchronisation does not naturally handle. A cert-manager needs to be running before you can create Certificate resources. An operator needs its CRDs installed before you can create instances of the custom resource.
Flux’s kustomize-controller handles this through the dependsOn field, which lets you declare that one Kustomization should not reconcile until another has successfully synced. ArgoCD handles it through sync waves, where resources annotated with different wave numbers are applied in sequence within a single sync operation.
| Concern | ArgoCD Approach | Flux Approach |
| Dependency ordering | Sync waves via annotations | dependsOn field in Kustomization |
| Secret management | Sealed Secrets, Vault plugin | SOPS integration, external-secrets |
| Policy enforcement | AppProject RBAC | Tenant model with kustomize patches |
Secrets in a GitOps World
The question of how to handle secrets without storing them in plaintext in Git is the first thing engineers ask when they move toward GitOps properly. A few approaches have matured in the ecosystem.
Sealed Secrets encrypts secret values using a public key whose corresponding private key lives only in the cluster. The encrypted blob can be safely committed to Git. On the cluster, the controller decrypts it and creates the native Kubernetes Secret. This is simple to operate but creates key rotation complexity.
External Secrets Operator takes a different stance. Rather than storing encrypted secrets in Git, it stores a reference to a secret in an external system like AWS Secrets Manager, GCP Secret Manager, or HashiCorp Vault. The operator fetches and syncs the actual value at runtime. This aligns better with organisations that already have a secrets management platform and want GitOps to work alongside it rather than replace it. The
Askan’s platform engineering practice helps teams design GitOps architectures that scale without accumulating operational debt. You can explore the full range of platform and DevOps work at
When to Move Beyond ArgoCD
Moving away from ArgoCD is rarely the right decision. Moving beyond a single ArgoCD installation is often necessary and does not mean abandoning the tool. The signal that it is time to evolve your GitOps architecture is not tool limitations so much as organisational friction.
When platform teams are becoming a bottleneck because application teams cannot self-serve their deployment configuration, the architecture needs to change. When drift detection is happening only for some clusters because the tooling does not cover the full fleet, coverage is the problem. When multi-cluster rollout of a new platform component takes weeks because there is no fleet-level synchronisation, templating is the gap.
Most large engineering organisations that have done this work well arrive at a layered model. A central platform team manages the GitOps tooling itself and the cluster fleet configuration. Application teams manage their own application GitOps configurations within guardrails defined by the platform layer. This is, at its core, a platform engineering problem as much as a tooling one.
Most popular pages
-
From Prototype to Production: The Engineering Checklist That Actually Matters
Prototypes lie. They perform well in demos because they are not doing any of the work that production systems actually do. There is no...
-
Building a Developer Experience (DX) Platform: From Golden Paths to Self-Service Infrastructure
There is a measurement problem at the heart of platform engineering. The people who benefit most from a well-built internal developer platform are often...
-
Search Infrastructure for Applications: Elasticsearch vs OpenSearch vs Typesense
Search is one of those features that seems straightforward until you try to build it properly. A basic LIKE query handles small datasets. The...
From Prototype to Production: The Engineering Checklist That Actually Matters
Prototypes lie. They perform well in demos because they are not doing any of the work that production systems actually do. There is no...
Building a Developer Experience (DX) Platform: From Golden Paths to Self-Service Infrastructure
There is a measurement problem at the heart of platform engineering. The people who benefit most from a well-built internal developer platform are often...
Search Infrastructure for Applications: Elasticsearch vs OpenSearch vs Typesense
Search is one of those features that seems straightforward until you try to build it properly. A basic LIKE query handles small datasets. The...