



TABLE OF CONTENTS
Building a Developer Experience (DX) Platform: From Golden Paths to Self-Service Infrastructure

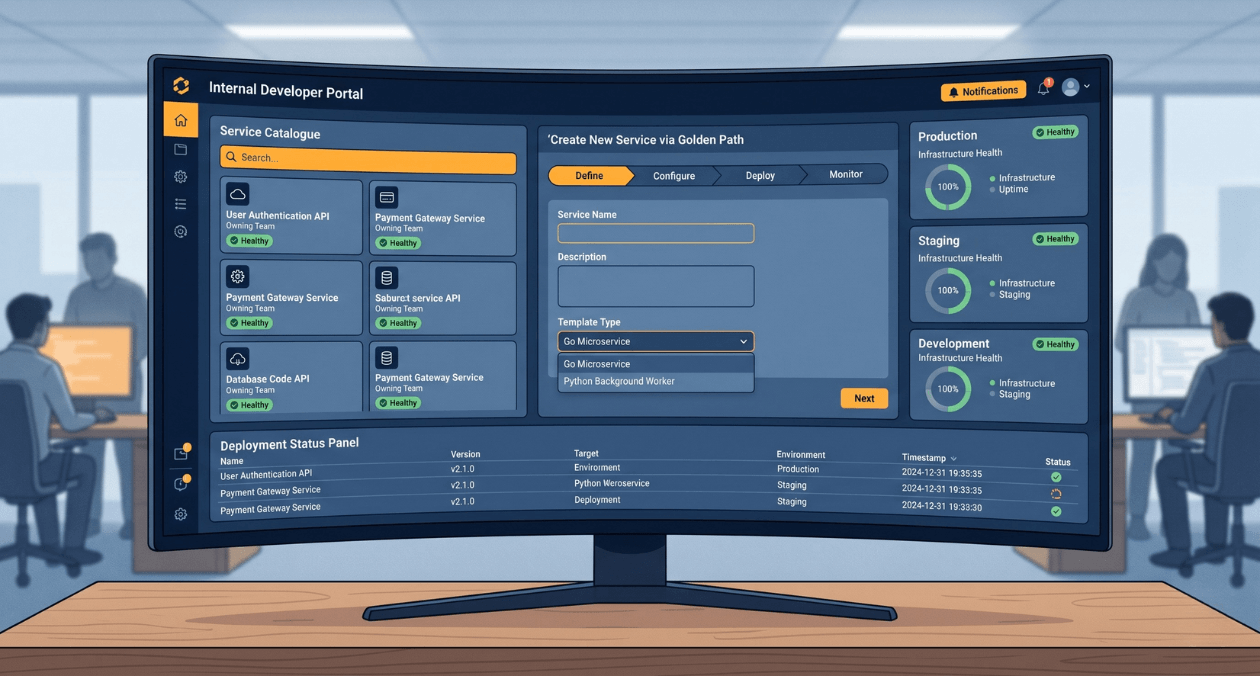
There is a measurement problem at the heart of platform engineering. The people who benefit most from a well-built internal developer platform are often the least aware of its existence. When a developer spins up a new service in fifteen minutes using a scaffold template, runs tests in a consistent CI pipeline, deploys to a staging environment with a single command, and gets observability set up automatically, none of that feels like a platform. It just feels like things working the way they should. That invisibility is the goal. It is also why platform teams struggle to articulate their value and why DX platforms are chronically underfunded relative to their impact on engineering productivity.
This guide is written for engineering directors and platform teams who are either building a developer experience platform from scratch or evolving an informal collection of shared tooling into something more deliberate. The concepts of golden paths, self-service infrastructure, and internal developer portals have moved from conference talks into serious engineering practice over the last three years. Understanding what they mean in concrete terms, how they relate to each other, and what a realistic build roadmap looks like is increasingly important for any organisation with more than a handful of engineering teams.
The platform engineering discipline is maturing quickly. The CNCF Platforms White Paper defines an internal developer platform as a layer of capabilities provided by a platform team that product teams can use to build, deploy, and operate their services without deep expertise in the underlying infrastructure. That definition is useful because it emphasises the service relationship at the heart of platform work: the platform team serves product engineering teams, and the measure of success is whether those teams can move faster and more safely because of the platform.
What a Developer Experience Platform Actually Is
A DX platform is not a single product or tool. It is a collection of capabilities, interfaces, and conventions that together reduce the cognitive load and friction in a product engineer’s daily work. The components that constitute a mature DX platform typically include a service scaffolding system that generates new services from opinionated templates, a CI/CD pipeline layer that product teams can use without configuring from scratch, an environment provisioning capability that lets teams spin up and tear down environments on demand, a secrets and configuration management layer, an observability setup that is pre-wired into every new service, and a developer portal that surfaces all of this through a unified interface.
Not every organisation needs all of these components, and most DX platforms are assembled incrementally over time rather than built in a single programme. The unifying principle across all of them is the same: move decisions about how infrastructure is provisioned, how services are deployed, and how operational concerns are handled out of individual product teams and into shared platform capabilities with well-designed defaults. Product engineers should spend their time building product, not solving infrastructure problems that someone else on a different team already solved last quarter.
The term developer experience captures something important that pure infrastructure tooling often misses. A platform that is technically complete but difficult to use, poorly documented, or slow to iterate on is not a good developer experience. The user of a DX platform is an engineer with high expectations, strong opinions, and the ability to work around any platform that creates more friction than it removes. Platform teams that treat product engineers as customers rather than users of mandated tooling consistently build better platforms. This mindset connects directly to how mature engineering organisations think about full-stack developer productivity and tooling investment.
Golden Paths: Opinionated Defaults That Accelerate the Majority
The golden path concept, popularised in the platform engineering community largely through Spotify’s writing on its Backstage developer portal, describes a pre-built, well-maintained route through the infrastructure landscape that represents the recommended way to accomplish a common engineering task. Creating a new microservice, setting up a database for a new product, adding a background worker, or wiring up a new API endpoint all have golden paths in organisations that have invested in platform engineering.
The key word is opinionated. A golden path is not a menu of choices. It is a specific, supported path that encodes the organisation’s decisions about language version, framework, testing approach, observability instrumentation, secret management, deployment strategy, and infrastructure configuration. When an engineer follows the golden path, they get all of those decisions made for them and can focus entirely on the business logic of their service. The platform team owns the path and keeps it updated. Product engineers follow it and benefit from it.
Golden paths work because most engineering tasks in a given organisation are variations on a small number of patterns. A Node.js API service backed by PostgreSQL is not a unique architecture. It is a pattern that dozens of teams in the same organisation are implementing in slightly different ways, accumulating slightly different configurations, and creating slightly different operational profiles as a result. A golden path replaces that variation with a single, maintained, tested implementation that everyone uses. The cost of building the path is paid once. The benefit of not solving the same problem fifty times is paid continuously.
It is important to distinguish between a golden path and a mandate. Platform teams that force engineers onto a single path regardless of their use case create resentment and workarounds. The more effective model is to make the golden path so much easier and better-supported than the alternatives that engineers choose it willingly. Teams that need to deviate from the path can do so, but they accept that they are outside the supported path and own the operational consequences. This balance between convention and escape hatch is one of the most important design decisions a platform team makes.
Golden Path Components and What They Standardise
| Golden Path Component | What It Standardises | Benefit to Product Teams |
|---|---|---|
| Service scaffold template | Language version, framework, project structure, linting config | New service ready in minutes, not hours |
| CI pipeline template | Test stages, coverage thresholds, security scanning, build steps | No pipeline setup, consistent quality gates |
| Infrastructure module | Cloud resource provisioning, tagging, networking, IAM patterns | Correct-by-default infra, no config drift |
| Observability bootstrapping | Metrics, tracing, logging, alerting wired into every service | Instant visibility without manual setup |
| Secrets management pattern | Vault or cloud secrets manager integration, rotation, access model | No ad-hoc secret handling, audit trail |
| Deployment pattern | Deployment strategy, rollback, canary or blue-green config | Safe deployments without bespoke scripts |
esign Your Internal Developer Platform
Self-Service Infrastructure: The Operational Model That Makes DX Work
Self-service infrastructure is the capability that allows product engineers to provision, configure, and manage the resources they need without submitting tickets to an infrastructure team and waiting for approval. It is the operational model that makes a DX platform genuinely useful rather than just well-documented. Without self-service, engineers still experience the friction of waiting for someone else to do infrastructure work, even if the platform has excellent golden paths for every common pattern.
The technical foundation of self-service infrastructure is infrastructure as code combined with appropriate guardrails. Platform teams define the approved modules and patterns, typically in Terraform, Pulumi, or a Kubernetes operator framework. Product teams use those modules to provision their own resources, within the boundaries the platform team has defined. The platform team approves the patterns, not the individual provisioning requests. This is the model that shifts platform teams from being a bottleneck to being an enabler.
Guardrails are the critical complement to self-service. Unlimited self-service without guardrails produces security misconfigurations, cost overruns, and compliance gaps. The guardrail model works by encoding the organisation’s policies into the infrastructure modules themselves. A database module that always enables encryption at rest and always applies the correct network policy means product teams cannot provision a non-compliant database even if they try to. The policy is in the module, not in a review process. This approach produces more consistent compliance than manual review at a fraction of the operational overhead, and it scales as the number of product teams grows.
The maturity journey for self-service infrastructure typically moves through three stages. In the first stage, the platform team provisions everything and product teams make requests. In the second stage, approved Terraform modules exist but product teams still submit pull requests to a shared infrastructure repository for review. In the third stage, product teams own their own infrastructure code within defined boundaries, the modules enforce the guardrails automatically, and the platform team’s role shifts to maintaining the modules and evolving the golden paths. Most organisations with more than twenty engineers are somewhere between stages one and two, with the gap to stage three being primarily a cultural and process change rather than a technical one.
The Internal Developer Portal: Making Everything Discoverable
A developer portal is the user interface of a DX platform. It is the place where engineers go to understand what capabilities the platform offers, discover existing services and their ownership, find the golden path for their next task, and get visibility into the operational state of services they own or depend on. Without a portal, the DX platform exists as a collection of repositories, runbooks, and tribal knowledge that new engineers cannot navigate efficiently and experienced engineers use inconsistently.
Backstage, the open source developer portal framework originally built by Spotify and now a CNCF project, has become the de facto starting point for internal developer portals in organisations willing to invest in the build effort. Its software catalogue model, where every service, library, API, and resource is represented as a catalogued entity with ownership, documentation, and dependency relationships, solves the discoverability problem that grows as engineering organisations scale. The scaffolding plugin, which ties directly into the golden path concept, lets engineers launch new services from curated templates directly from the portal interface.
The build versus buy decision for a developer portal is real and worth taking seriously. Backstage requires meaningful engineering investment to set up, maintain, and extend. Commercial alternatives like Port, Cortex, and OpsLevel offer faster time to value with less ongoing maintenance burden. The right choice depends on the size of your engineering organisation, the complexity of your existing tooling ecosystem, and the capacity your platform team has for internal tooling work. For organisations with fewer than 50 engineers, a lightweight combination of a documentation site, a service registry, and standardised templates often delivers more value than a full Backstage implementation. For organisations with hundreds of engineers across multiple teams, the investment in a full developer portal consistently pays off over time.
Developer Portal Build vs Buy Considerations
| Factor | Build (Backstage) | Buy (Port, Cortex, OpsLevel) |
|---|---|---|
| Time to first value | Weeks to months | Days to weeks |
| Customisation depth | Full control via plugins | Limited to vendor extensibility model |
| Maintenance burden | High, owned by platform team | Low, managed by vendor |
| Integration flexibility | Any tool via custom plugin | Pre-built integrations, some gaps |
| Cost | Engineering time, infrastructure | Subscription, scales with team size |
| Best for | Large orgs with platform team capacity | Growing teams wanting fast setup |
Platform Team Topology: Who Builds and Owns the DX Platform
The team topology question is as important as the technical architecture question for DX platforms. Platform teams built on the wrong model consistently become bottlenecks, build things product teams do not want, or drift into pure infrastructure operations without the product thinking that makes a DX platform genuinely useful.
The most effective platform teams operate as product teams for their internal customers. They have a roadmap, they conduct discovery with product engineering teams to understand pain points and workflow friction, they measure adoption and developer satisfaction, and they iterate based on feedback. This is a fundamentally different operating model from a traditional infrastructure team that responds to tickets and manages production environments. The Team Topologies framework, developed by Matthew Skelton and Manuel Pais, describes this as a platform team with a clear interaction mode of X-as-a-Service toward the stream-aligned teams that build product. The Team Topologies model has become the standard reference for how engineering organisations structure their team relationships around enabling fast flow.
Staffing a platform team correctly is a consistent challenge. The skill profile is genuinely broad: platform engineers need backend development skills, infrastructure and cloud expertise, DevOps tooling knowledge, and product thinking. This combination is rare, which is why many platform teams end up over-indexed on infrastructure operations and under-indexed on the developer experience and product design skills that make the platform genuinely useful to product engineers. Engineering directors building platform teams should weight the hiring criteria toward engineers who have worked on product teams and understand developer workflow from that perspective, not only toward infrastructure specialists.
The question of how large a platform team should be relative to product engineering headcount has no universal answer, but a ratio of roughly one platform engineer per ten to fifteen product engineers is commonly cited as a starting point. Below this ratio, the platform team is spread too thin to maintain existing capabilities while iterating on new ones. Above it, the platform team risks building capabilities that go beyond what product teams actually need, which is its own kind of waste. This connects to the broader software engineering team capability trends shaping how organisations structure their work.
esign Your Internal Developer Platform
Measuring DX Platform Success: Metrics That Actually Matter
Platform teams that cannot measure their impact are vulnerable to being deprioritised when engineering headcount decisions are made. The challenge is that the most important outcomes of a DX platform, developer productivity and cognitive load reduction, are genuinely difficult to measure directly. The metrics that matter most are the ones that proxy these outcomes with enough precision to be useful for investment decisions.
DORA metrics, the four key metrics from the DevOps Research and Assessment programme, provide the most widely validated framework for measuring software delivery performance. Deployment frequency, lead time for changes, change failure rate, and time to restore service collectively capture whether a development organisation is delivering quickly and reliably. A platform team that improves golden paths and CI/CD tooling should see deployment frequency increase and lead time decrease as a direct consequence of that work. These are the metrics that connect platform investment to business outcomes in language that engineering directors and CTOs can present to the wider business.
Platform-specific metrics complement DORA metrics and give the platform team visibility into adoption and health at the component level. The time from a developer deciding to create a new service to having it running in a staging environment, often called time to production-ready, is a direct measure of golden path effectiveness. Golden path adoption rate, the percentage of new services created via the scaffold versus from scratch, measures whether the path is genuinely preferred by engineers or being avoided. Self-service ratio, the percentage of infrastructure changes that do not require platform team involvement, measures whether the self-service model is working as intended.
Developer satisfaction surveys, run quarterly, provide qualitative signal that quantitative metrics miss. A platform that scores well on all quantitative metrics but generates frustration among product engineers is a platform with hidden problems. Conversely, a platform that engineers feel genuinely positive about tends to have higher adoption and delivers compounding value over time as more teams contribute feedback and the platform evolves in response. Regular, lightweight surveys asking three or four targeted questions about the biggest friction points in the development workflow are one of the highest-ROI inputs a platform team can have.
DX Platform Metrics Framework
| Metric | What It Measures |
|---|---|
| Deployment frequency | How often teams ship to production |
| Lead time for changes | Time from commit to running in production |
| Time to production-ready | Speed of the golden path for new services |
| Golden path adoption rate | Percentage of services using the scaffold |
| Self-service ratio | Infrastructure changes without platform ticket |
| Developer satisfaction score | Quarterly survey on workflow friction |
| Change failure rate | Percentage of deployments causing incidents |
A Realistic Build Roadmap for Engineering Directors
Most DX platform build efforts fail not because the technology is wrong but because the scope is too ambitious and the feedback loops are too long. The teams that build durable platforms do so incrementally, starting with the highest-friction problems in their current engineering workflow and building outward from there.
A realistic roadmap for an organisation starting a DX platform effort begins with discovery. Spend four to six weeks talking to product engineering teams to identify the three most common workflow friction points. Not the most technically interesting problems, but the most commonly experienced ones. This discovery work almost always surfaces the same categories: inconsistent CI/CD configuration, environment provisioning friction, observability setup overhead, and service bootstrapping time. These are the problems the platform team should solve first.
The first golden path should be for the most common service type in the organisation. If eighty percent of new services are REST APIs, the first golden path is for a REST API. Build it, test it with two or three willing product teams, iterate on the feedback, and measure whether it actually reduces the time to production-ready. When it does, extend coverage to the next most common pattern. This incremental approach delivers visible value quickly, builds credibility with product teams, and gives the platform team real usage data to inform the next investment.
Self-service infrastructure should follow the golden paths, not precede them. It is easier to build self-service capabilities on top of well-defined patterns than to build them generically. The developer portal should come last, once there is enough catalogue content, enough golden paths, and enough self-service capability to justify the investment in a unified interface. Building a portal to surface a thin platform is a common mistake that results in a portal that nobody uses because it does not solve enough real problems yet.
This same discipline of sequencing investment to match actual product readiness applies broadly in engineering strategy. As the Askan team has explored in analysis of Angular vs React for scalable frontend architecture decisions, the right technology choice is always contextual and timed to when the team has the maturity to absorb it, not simply when it becomes technically available. The same principle applies to platform capabilities: build what the organisation is ready to use and maintain, not what looks impressive in an architecture diagram.
Most popular pages
-
From Prototype to Production: The Engineering Checklist That Actually Matters
Prototypes lie. They perform well in demos because they are not doing any of the work that production systems actually do. There is no...
-
Search Infrastructure for Applications: Elasticsearch vs OpenSearch vs Typesense
Search is one of those features that seems straightforward until you try to build it properly. A basic LIKE query handles small datasets. The...
-
Cost-Aware Engineering: Teaching Teams to Think About Resource Spend During Development
There is a gap inside most engineering organisations that rarely shows up in a sprint retrospective but shows up very clearly in quarterly cloud...
From Prototype to Production: The Engineering Checklist That Actually Matters
Prototypes lie. They perform well in demos because they are not doing any of the work that production systems actually do. There is no...
Search Infrastructure for Applications: Elasticsearch vs OpenSearch vs Typesense
Search is one of those features that seems straightforward until you try to build it properly. A basic LIKE query handles small datasets. The...
Cost-Aware Engineering: Teaching Teams to Think About Resource Spend During Development
There is a gap inside most engineering organisations that rarely shows up in a sprint retrospective but shows up very clearly in quarterly cloud...