



TABLE OF CONTENTS
Search Infrastructure for Applications: Elasticsearch vs OpenSearch vs Typesense

Search is one of those features that seems straightforward until you try to build it properly. A basic LIKE query handles small datasets. The moment your corpus grows, your users start expecting typo tolerance, faceted filtering, relevance ranking, and sub-100-millisecond response times, that LIKE query stops being an answer. Every application that stores content, products, users, or documents eventually reaches the point where it needs a dedicated search layer, and that is when engineers discover just how much variation exists in the search infrastructure landscape.
In 2026, three names dominate the conversation for backend engineers building application search: Elasticsearch, OpenSearch, and Typesense. Each has a distinct history, architecture philosophy, and set of tradeoffs. Elasticsearch built the modern search tooling category. OpenSearch forked it to preserve open source access. Typesense arrived as a purpose-built alternative optimised for developer experience and instant search. Choosing among them is not purely a performance question. It involves licensing, operational overhead, search feature requirements, and team capability.
This comparison guide covers all three across the dimensions that actually drive selection decisions for backend engineers and architects. The goal is not to name a winner but to give you a clear framework for identifying which tool fits your specific application context. Just as backend database decisions between MongoDB and relational databases come down to the shape of your data and query patterns, search infrastructure choices come down to the shape of your search workload and operational constraints.
The Origin Story: Why Three Tools Exist for the Same Problem
Elasticsearch was built by Elastic and released in 2010 as an open source distributed search and analytics engine built on top of Apache Lucene. For over a decade it was the default answer for any serious search requirement. Its query DSL, index management, and distributed architecture became the reference model for what enterprise search infrastructure looked like.
In January 2021, Elastic changed Elasticsearch’s license from the Apache 2.0 open source license to the Server Side Public License (SSPL) and the Elastic License, which restrict how cloud providers can offer Elasticsearch as a managed service. This move prompted AWS to fork Elasticsearch 7.10, the last Apache-licensed version, and create OpenSearch as a fully open source, Apache 2.0 licensed alternative. OpenSearch is now governed by the OpenSearch Project and maintained by AWS with broad community contributions.
Typesense predates the fork, having been founded in 2016 with a different ambition entirely. Rather than forking an existing system, Typesense was written from scratch in C++ with a focus on instant search, developer simplicity, and predictable performance at application scale. It is not trying to be a replacement for Elasticsearch on all axes. It is trying to be the right tool for product search, site search, and autocomplete workloads where ease of integration and speed matter more than analytics depth. According to Typesense’s official documentation, its architecture stores the entire search index in memory with a disk-backed persistence layer, which is the core reason for its speed profile.
Core Architecture Differences
Elasticsearch
Elasticsearch is a distributed document store and search engine built on Lucene. Documents are stored in indices, which are divided into shards distributed across nodes in a cluster. Its query language, the Query DSL, is powerful and expressive, supporting full-text search, aggregations, geo queries, vector search with k-NN, and complex boolean logic. This power comes with operational complexity. Running a production Elasticsearch cluster requires attention to shard allocation, heap sizing, index lifecycle management, and JVM tuning. The learning curve for operations is steeper than for the other two options.
Elasticsearch’s licensing, now split between SSPL and the Elastic License 2.0, means it is free to run self-hosted but not free for cloud providers to offer as a managed service without restrictions. For most engineering teams running their own infrastructure, this distinction does not matter in practice. For teams building products they intend to offer to customers as managed services, it requires a closer read of the license terms.
OpenSearch
OpenSearch is architecturally very close to Elasticsearch 7.10, the version it was forked from. The query API, index management model, and cluster architecture are largely compatible, which means most knowledge of Elasticsearch transfers directly to OpenSearch. The OpenSearch documentation explicitly maintains API compatibility as a project goal, though newer Elasticsearch features released after the fork do not have direct OpenSearch equivalents and vice versa. OpenSearch is fully Apache 2.0 licensed, which makes it the straightforward choice for teams that need the capabilities of Elasticsearch but want an unrestricted open source license or prefer to run on AWS OpenSearch Service as a fully managed offering.
Since the fork, OpenSearch has developed its own roadmap, adding features like neural search, vector database capabilities, and ML inference integration through its ML Commons plugin. For teams already running on AWS infrastructure, the managed OpenSearch Service removes much of the operational burden that makes self-hosted Elasticsearch challenging at scale.
Typesense
Typesense is the most architecturally distinct of the three. Written in C++ rather than Java, it maintains the entire search index in RAM with on-disk persistence. This design choice produces very low and predictable search latency, typically single-digit milliseconds at p99, without JVM garbage collection pauses or heap tuning. The tradeoff is that dataset size is constrained by available memory, which makes Typesense well-suited for application-scale search datasets (millions of documents) but less appropriate for log analytics, telemetry, or large-corpus enterprise search where datasets are measured in hundreds of gigabytes or terabytes.
Typesense’s schema definition is explicit and typed, which keeps the API surface clean and makes integration straightforward. Its typo tolerance is built-in and works well out of the box without query-level configuration. Faceted filtering, sorting, grouping, and geosearch are all supported. The Typesense Cloud managed offering and the ability to run it as a single binary with no external dependencies are significant advantages for teams that want strong search capability without the operational surface area of an Elasticsearch or OpenSearch cluster.
Architecture Comparison at a Glance
| Dimension | Elasticsearch | OpenSearch | Typesense |
|---|---|---|---|
| Language | Java (JVM) | Java (JVM) | C++ |
| Storage model | Lucene segments, disk | Lucene segments, disk | In-memory + disk persistence |
| License | Elastic License 2.0 / SSPL | Apache 2.0 | GPL-3 (self-host), Typesense Cloud |
| Managed option | Elastic Cloud | AWS OpenSearch Service | Typesense Cloud |
| Query language | Query DSL (JSON) | Query DSL (JSON) | REST API with typed schema |
| Best dataset size | GB to TB | GB to TB | Up to ~50GB in memory |
Search Feature Depth: What Each Tool Handles Well
Full-Text Search and Relevance
All three tools handle standard full-text search competently. The differences emerge in the depth of relevance tuning available. Elasticsearch and OpenSearch expose the full Lucene relevance model, including BM25 scoring, custom boosting functions, field-level weight tuning, and learning to rank. This depth is valuable for enterprise search, content discovery, and e-commerce search where relevance is a product decision requiring ongoing tuning. Typesense uses its own relevance model with a simpler but effective set of tuning options including field-level weights, pinning, and ranking rules. For most product search use cases, Typesense’s model is sufficient and requires less configuration to produce good results out of the box.
Typo Tolerance and Fuzzy Search
This is one of Typesense’s strongest differentiators. Typo tolerance is built into Typesense at the core of its search model and works automatically without query-level fuzzy configuration. For product search, autocomplete, and site search where user input is unpredictable, this out-of-the-box behavior is genuinely useful. Elasticsearch and OpenSearch support fuzzy queries and n-gram analysis for typo tolerance, but these require deliberate index configuration and query-level settings to work well. The configuration overhead is not high for an experienced engineer, but it is a step that must be taken intentionally rather than being the default.
Vector Search and AI-Enhanced Retrieval
All three tools now support vector search, which has become essential for semantic search, recommendation systems, and retrieval-augmented generation (RAG) architectures. Elasticsearch’s kNN search is mature and battle-tested for production vector workloads. OpenSearch added neural search capabilities through its ML Commons plugin and supports approximate nearest neighbour search with FAISS and Lucene backends. Typesense added vector search support and supports hybrid search combining keyword and vector results, which is the pattern most useful for product and content search in 2026. For teams building on top of LLM infrastructure, this capability connects search to the broader trends in software engineering practices evolving around AI tooling.
Analytics and Aggregations
This is where Elasticsearch and OpenSearch clearly separate from Typesense. Both Elasticsearch and OpenSearch provide a rich aggregation framework supporting time-series analytics, histograms, terms aggregations, nested aggregations, and pipeline aggregations. These capabilities make them appropriate for log analytics, metrics dashboards, and business intelligence workloads alongside search. Typesense’s grouping and faceting features cover the aggregation needs of product search and filtering but are not designed for analytics at the depth that Elasticsearch or OpenSearch support. If your use case combines search and analytics in the same data layer, Elasticsearch or OpenSearch is the right fit.
Need Help Selecting Search Infrastructure?
Feature Fit by Use Case
| Use Case | Best Fit | Reason |
|---|---|---|
| E-commerce product search | Typesense or Elasticsearch | Typo tolerance, facets, relevance tuning |
| Log analytics and observability | Elasticsearch or OpenSearch | Rich aggregations, time-series support |
| Site search / documentation | Typesense | Fast setup, instant search, low ops overhead |
| Semantic / RAG search | Elasticsearch or OpenSearch | Mature vector search, hybrid retrieval |
| Autocomplete at scale | Typesense | In-memory speed, built-in prefix search |
| Enterprise content search | Elasticsearch or OpenSearch | Advanced relevance, access control, plugins |
Operational Complexity and Developer Experience
For backend engineers and architects, the operational surface area of a search system is as important as its feature set. A search engine that requires three engineers to operate is a different proposition from one that a team can run alongside other infrastructure responsibilities. This is where the three tools diverge significantly.
Running a self-hosted Elasticsearch or OpenSearch cluster requires meaningful operational knowledge. JVM heap configuration, shard allocation strategy, index lifecycle management, cluster state management, and rolling upgrades all require deliberate attention. The managed offerings from Elastic Cloud and AWS OpenSearch Service remove most of this burden but introduce cloud spend and vendor dependency. For teams where search is a core product feature and the team has the operational maturity to manage it, self-hosted Elasticsearch or OpenSearch is a viable choice. For teams where search is one feature among many and operational simplicity is a priority, the managed services are often the right tradeoff, similar to how full-stack teams increasingly rely on managed services to reduce operational overhead across the stack.
Typesense has a materially different operational profile. It ships as a single binary with no external dependencies. A production Typesense instance can be running in minutes. Its clustering model is simpler than Elasticsearch or OpenSearch, using a Raft-based consensus protocol for high availability. The Typesense Cloud managed offering further reduces this to zero operational overhead. For engineering teams that want strong search capability without investing in search infrastructure expertise, Typesense’s operational simplicity is a genuine competitive advantage over the other two options.
Developer experience is another dimension where Typesense consistently receives positive feedback. Its REST API is clean and consistent, its SDK support covers all major languages, and the documentation is oriented toward getting a working integration quickly. Elasticsearch and OpenSearch have comprehensive documentation but the query DSL’s depth means there is a steeper learning curve before engineers are productive with advanced search requirements. For teams onboarding new engineers onto a search-heavy codebase, Typesense reduces the ramp-up time measurably.
Operational Comparison
| Factor | Elasticsearch / OpenSearch | Typesense |
|---|---|---|
| Self-host complexity | High (JVM, shard management, ILM) | Low (single binary, simple cluster setup) |
| Managed service | Elastic Cloud / AWS OpenSearch | Typesense Cloud |
| Time to first search | Minutes to hours (cluster setup) | Minutes (single binary) |
| Upgrade process | Rolling upgrades, version compatibility checks | Standard binary replacement |
| Monitoring surface | Rich (metrics, logs, alerts) | Basic built-in, extends via external APM |
Licensing and Cost: The Practical Considerations
Licensing is a topic that engineering teams sometimes treat as a legal detail rather than an architectural input. For search infrastructure, it deserves more attention than it typically gets.
OpenSearch is the cleanest choice from a licensing standpoint. Apache 2.0 means you can use it, modify it, and build commercial products with it without restriction. If your organisation has policies around SSPL or Elastic License software, OpenSearch removes the licensing question entirely. The AWS OpenSearch Service pricing is compute-based and predictable, and the open source nature of the project means no vendor lock-in at the software level.
Elasticsearch’s Elastic License 2.0 is permissive for most use cases. You can use it in production applications, modify it, and distribute modifications, provided you do not offer it as a managed service or circumvent the license key enforcement. For the vast majority of engineering teams running Elasticsearch to power their own application’s search, the license does not create any practical restriction. The issue arises specifically for SaaS products that want to include Elasticsearch as a search component in a managed offering they sell to customers.
Typesense uses GPL-3 for the open source version and a commercial license for Typesense Cloud and enterprise deployments. GPL-3 has implications for products that embed Typesense and distribute the binary. Teams that run Typesense as a standalone service accessed via API, which is the standard integration pattern, are not typically affected by the GPL-3 copyleft requirements. For embedded use cases or proprietary distributions, a legal review is warranted.
Need Help Selecting Search Infrastructure?
Making the Decision: Signals That Should Drive Your Choice
Choose Elasticsearch When
Your use case combines search with analytics, log aggregation, or metrics. Your team has or is building expertise in Lucene-based search and relevance tuning is a core product concern. You need the deepest ecosystem of integrations, plugins, and tooling. Your dataset is large and distributed architecture is a requirement rather than a choice. You are already invested in the Elastic stack with Kibana dashboards and Logstash pipelines.
Choose OpenSearch When
You need Elasticsearch-level capabilities under a fully open source license. Your infrastructure is primarily on AWS and the managed OpenSearch Service reduces your operational burden meaningfully. You want to avoid SSPL licensing constraints for any reason. You are migrating from Elasticsearch 7.x and want minimal query compatibility changes. Vector search and neural search capabilities on AWS managed infrastructure are important to your roadmap.
Choose Typesense When
Your use case is product search, site search, autocomplete, or any search surface where instant response and typo tolerance are primary requirements. Your team values developer experience and operational simplicity over deep analytics capability. Your dataset fits comfortably in memory, typically under 50 to 100 million documents depending on document size and available RAM. You want to run search as a service with minimal infrastructure knowledge required. You are building a new search integration and want the fastest path from zero to a working, well-performing search experience.
One pattern increasingly seen in 2026 is using Typesense for user-facing search and Elasticsearch or OpenSearch for internal analytics and log search within the same organisation. The two tools serve genuinely different masters and a polyglot search infrastructure is a legitimate architectural choice when the workloads warrant it, in the same way that polyglot persistence is a mature pattern across relational and document databases.
Most popular pages
-
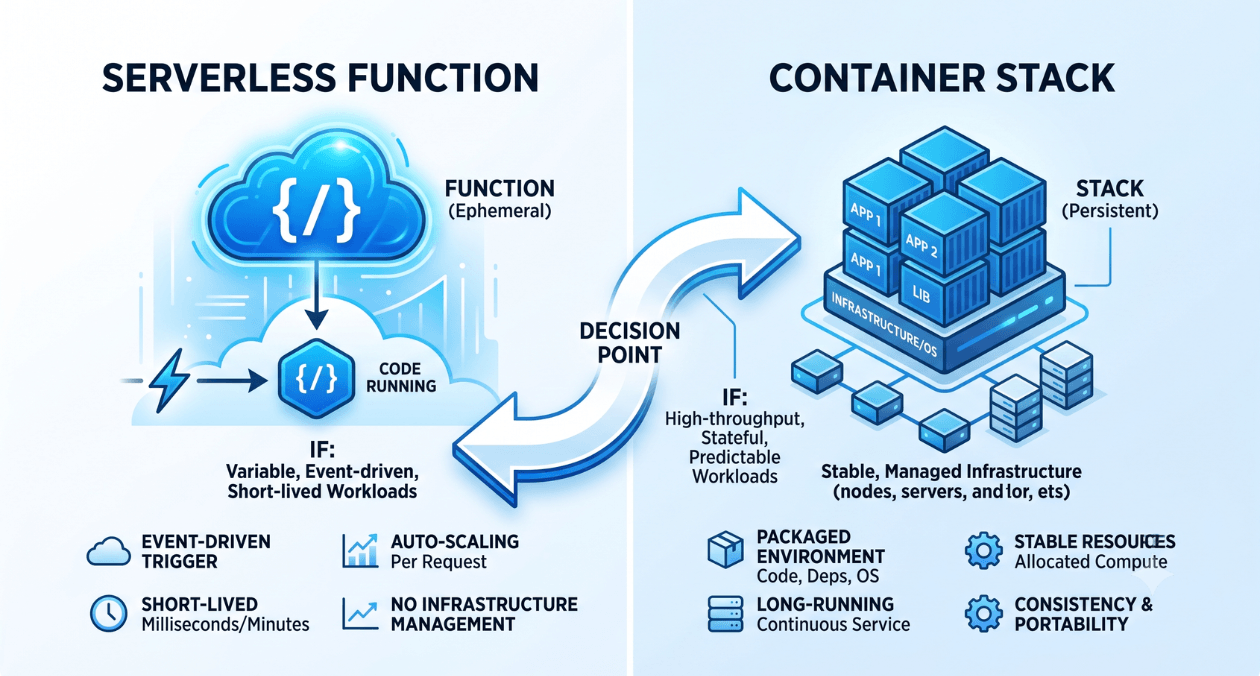
Serverless vs Containers: Choosing the Right Compute Model for Your Workload
Every engineering team building on the cloud eventually runs into this question: should this workload run on serverless functions or inside containers. The answer...
-
Postgres vs MySQL in 2026: Which Fits Modern Application Workloads Better
Every couple of years the Postgres versus MySQL debate resurfaces, and 2026 is no different. Teams building new applications still ask the same question...
-
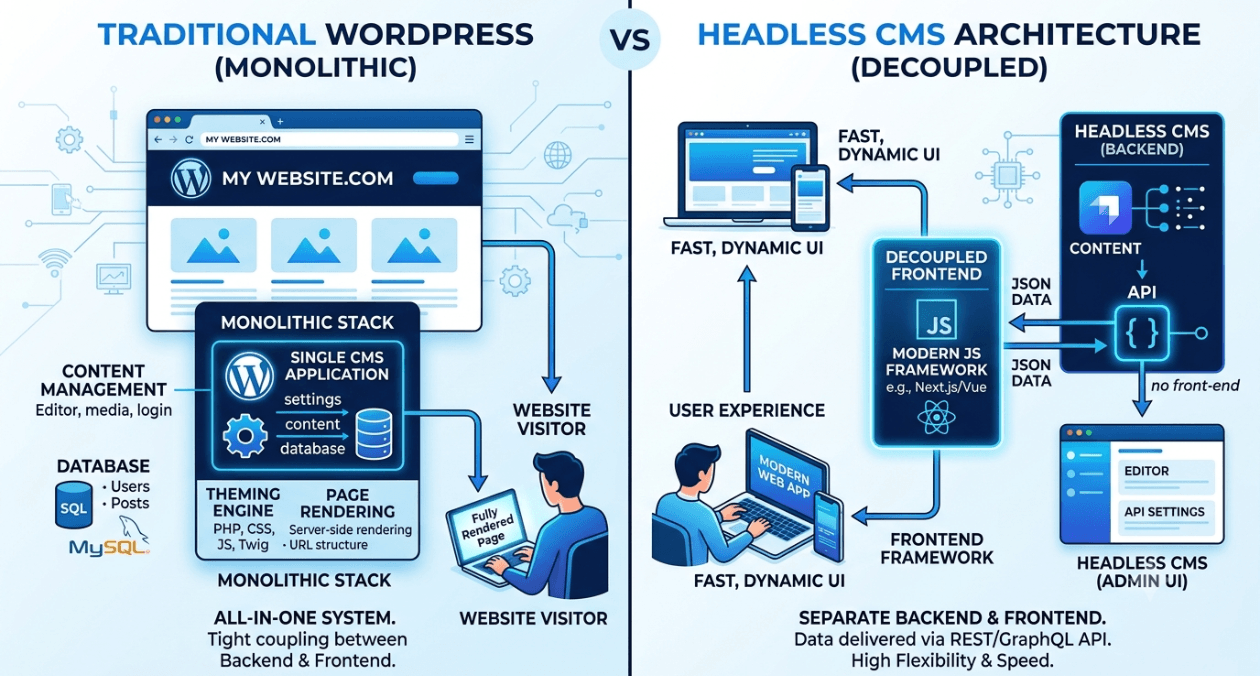
WordPress vs Headless WordPress: When Decoupling Actually Makes Sense
WordPress still runs a massive share of the web, and for good reason. It is fast to launch, familiar to content teams, and backed...
Serverless vs Containers: Choosing the Right Compute Model for Your Workload
Every engineering team building on the cloud eventually runs into this question: should this workload run on serverless functions or inside containers. The answer...
Postgres vs MySQL in 2026: Which Fits Modern Application Workloads Better
Every couple of years the Postgres versus MySQL debate resurfaces, and 2026 is no different. Teams building new applications still ask the same question...
WordPress vs Headless WordPress: When Decoupling Actually Makes Sense
WordPress still runs a massive share of the web, and for good reason. It is fast to launch, familiar to content teams, and backed...