



TABLE OF CONTENTS
From Prototype to Production: The Engineering Checklist That Actually Matters

Prototypes lie. They perform well in demos because they are not doing any of the work that production systems actually do. There is no real traffic generating concurrent load. There is no error handling for the inputs that real users will inevitably send. There is no logging that needs to be queried at 2 AM when something breaks. There is no secrets management, no database connection pooling, no graceful shutdown, no rate limiting. The prototype works because it exists in a controlled environment where none of those things have been tested yet.
The gap between a working prototype and a production-ready system is where most engineering incidents are born. Not because engineers are careless, but because the items that separate prototype quality from production quality are spread across a large surface area that is easy to partially cover and hard to cover completely without a deliberate process. A tech lead who has shipped ten production services has a mental checklist. A developer shipping their second service does not. And even experienced engineers miss items under deadline pressure without a written reference.
This guide is a practical checklist for engineering managers and tech leads who are taking a service from prototype or MVP quality to something that can run in production safely. It is not exhaustive for every possible system architecture. It is calibrated to the items that are most commonly skipped, that have the highest incident rates when skipped, and that are genuinely achievable before a go-live rather than belonging on a post-launch backlog. As covered in Askan’s broader look at software development practices evolving in 2025 and beyond, production readiness is increasingly treated as a first-class engineering concern rather than something addressed after the first outage.
Why Most Production Readiness Checklists Fail in Practice
Production readiness checklists exist at most engineering organisations. The problem is rarely their absence. It is that they are either too generic to be actionable, too long to be completed under realistic launch timelines, or treated as a compliance exercise where items get checked without the underlying work being done. A checkbox next to ‘add monitoring’ that gets ticked because a single health check endpoint exists is not monitoring. A checkbox next to ‘security review’ that gets ticked because no one raised an objection is not a security review.
The checklists that work in practice share three characteristics. First, they are specific enough to be verifiable. Not ‘add logging’ but ‘structured logs are emitted for every request with request ID, duration, status code, and error detail’. Second, they distinguish between hard gates that must be met before go-live and soft gates that are important but can be tracked as known gaps with a plan to close them. Not everything needs to be perfect on day one. The distinction between what is required and what is planned matters. Third, they are owned by the tech lead for the service, not by a central team that reviews and approves. Distributed ownership produces better outcomes than centralised gatekeeping.
Observability: You Cannot Fix What You Cannot See
Observability is consistently the item that gets partially completed and then marked as done. A service that emits metrics and logs but has no alerting is not observable in any meaningful production sense. A service with alerting but no runbooks for the alerts is observable but not operable. The full observability requirement for a production service covers four components and all four need to be in place before go-live.
Structured logging means every log entry is machine-readable, carries a correlation or request ID that connects logs across service boundaries, and includes enough context to understand what happened without reading surrounding log lines. Free-text logging is not structured logging. Log levels must be configured correctly and the DEBUG level must not be enabled in production by default, as this generates volume that makes logs unusable and drives storage costs up significantly.
Metrics should cover the four golden signals: latency, traffic, errors, and saturation. For HTTP services this means request rate, error rate, p50 and p99 latency, and resource utilisation for CPU, memory, and any connection pools. Custom business metrics that track the health of the service’s core function, such as order processing rate for a payment service or message delivery rate for a notification service, are equally important and often more actionable than infrastructure metrics when something goes wrong.
Distributed tracing should be instrumented from day one for any service that calls other services or databases. A trace that shows the full call graph for a request, with timing at every hop, is the difference between a fifteen-minute debugging session and a three-hour one when a latency regression appears after launch. OpenTelemetry has become the standard instrumentation library for tracing across all major languages and integrates with every major observability backend. There is no longer a good reason to skip distributed tracing for any service that participates in a call graph.
Alerting must be configured before go-live, not added after the first incident reveals that no one was notified. Alerts should fire on symptoms visible to users, error rate above threshold and latency p99 above SLA, rather than only on infrastructure signals like high CPU. Every alert should have a corresponding runbook that describes what the alert means, what the likely causes are, and what steps an on-call engineer should take. An alert without a runbook is noise that trains engineers to ignore alerts.
Observability Checklist: Hard Gates Before Go-Live
| Item | Requirement | Common Gap |
|---|---|---|
| Structured logging | JSON logs with request ID, status, duration, error detail | Free-text logging or missing correlation IDs |
| Log levels | DEBUG off in production, INFO for normal flow, ERROR for failures | DEBUG left on, causing log volume spikes |
| Four golden signals | Request rate, error rate, p50/p99 latency, saturation | Only infrastructure metrics tracked |
| Business metrics | Custom metrics for core service function | Only infra metrics, no domain visibility |
| Distributed tracing | OpenTelemetry instrumented, spans across service boundaries | Tracing skipped, blind during cross-service debugging |
| Alerting | Symptom-based alerts with p99 and error rate thresholds | No alerts, or infrastructure-only alerts |
| Runbooks | Runbook per alert covering causes and remediation steps | Alerts without runbooks, on-call confusion |
Security: The Items That Cannot Wait for a Post-Launch Hardening Sprint
Security hardening is the category most commonly deferred to a post-launch sprint that never happens. Some security items genuinely can be deferred. Others cannot, because the window to fix them closes the moment real user data enters the system. The distinction is between security items that protect data and the attack surface once the service is live, and security items that are hygiene improvements with no immediate exposure risk.
Secrets must not live in code, configuration files, or environment variables stored in plaintext in version control. This is not a nuanced tradeoff. A single secret committed to a repository that is later made public, or that is accessible to an engineer who leaves the company, represents a material security incident. All secrets should be stored in a secrets manager, Vault, AWS Secrets Manager, or an equivalent, and injected at runtime. Secret rotation should be tested before go-live, not planned for after.
Input validation must be applied at every external boundary. An API that accepts user input without validating type, length, and format before processing it is an injection attack waiting to be discovered. This applies to HTTP request parameters, request bodies, headers used in business logic, and any data read from queues or event streams that originates outside the service. Validation libraries exist for every major language and framework. Using them is not optional for a production service.
Authentication and authorisation on every external endpoint must be verified before go-live. This means testing that unauthenticated requests to protected endpoints return 401, that authenticated requests with insufficient permissions return 403, and that there are no endpoints that were intended to be internal but are accessible from the public network. Automated security scanning tools like OWASP ZAP or Snyk can surface the most common vulnerabilities quickly and should be part of the CI pipeline as covered in OWASP’s production security testing guidance.
Prepare Your Engineering Team for Go-Live
Reliability: What Happens When Things Go Wrong
A prototype handles the happy path. A production service handles every path, including all the ones that were not anticipated during development. Reliability engineering before go-live is about deliberately building the failure handling that protects users and the rest of the system when something breaks.
Graceful Degradation and Error Handling
Every external dependency in the service call graph, databases, downstream APIs, caches, message queues, should have explicit failure handling. What does the service return to its caller when the database is slow? When the downstream API returns a 500? When the cache is unavailable? These are not edge cases in production. They are routine occurrences that every service experiences eventually. The service should have a defined and tested behavior for each one, whether that is a cached fallback, a degraded response, or a clear error to the caller. Unhandled exceptions that produce 500 responses with stack traces visible to external callers are both a reliability problem and a security information leak.
Timeouts, Retries, and Circuit Breakers
Every network call in a production service must have a timeout. A service that makes an external API call without a timeout will hang indefinitely when that API is slow or unresponsive, exhausting connection pools and thread pools until the service itself becomes unavailable. Timeouts should be set to reflect the latency budget of the calling service, not the expected latency of the dependency.
Retry logic should be applied to transient failures with exponential backoff and jitter. Retrying immediately on failure without backoff amplifies load on a struggling dependency and can turn a partial outage into a total one. Circuit breakers should be considered for dependencies where failure is likely to be sustained rather than transient. An open circuit breaker that returns a fast failure is better for the overall system than a closed circuit that allows every request to wait until timeout. These patterns are covered in depth in the Askan team’s analysis of database connection pool reliability under production load, where the same failure handling principles apply.
Graceful Shutdown
Services deployed in containerised environments receive SIGTERM signals when being stopped for a rolling deployment, a scale-down event, or a node failure. A service that does not handle SIGTERM gracefully will drop in-flight requests when it is terminated. Graceful shutdown means stopping acceptance of new requests on receiving SIGTERM, allowing in-flight requests to complete up to a configured drain timeout, closing database connections and releasing other resources, and then exiting cleanly. This is a simple implementation that most frameworks support directly and that eliminates an entire class of deployment-related errors that are otherwise difficult to diagnose.
Reliability Checklist: Hard Gates Before Go-Live
| Item | Requirement | Risk if Skipped |
|---|---|---|
| Dependency timeouts | Every external call has an explicit timeout | Thread/connection pool exhaustion under slow deps |
| Retry with backoff | Transient failures retried with exponential backoff + jitter | Load amplification, cascading failures |
| Circuit breakers | Breakers on sustained-failure dependencies | Full service unavailability from one bad dep |
| Graceful shutdown | SIGTERM handled, in-flight requests drained | Dropped requests on every deployment |
| Error boundary | All unhandled exceptions return clean errors, not stack traces | Security info leak, confusing caller errors |
| Health check endpoints | Liveness and readiness probes configured and tested | Bad instances receive traffic, slow rollouts |
Performance: Validating That the System Holds Under Real Load
Prototype performance numbers are almost never representative of production performance. The prototype is not handling real concurrency, real data volumes, or the full set of code paths that production traffic exercises. Performance validation before go-live does not require a full load testing programme. It requires enough confidence that the system will not fall over at expected launch traffic.
The minimum performance validation for a go-live is a load test at expected peak traffic, held for long enough to expose memory leaks and connection pool exhaustion patterns that only appear under sustained load. Fifteen minutes at peak expected concurrency reveals the vast majority of performance problems that would otherwise appear in the first hour of production traffic. Tools like k6, Locust, and Artillery make this straightforward to set up against a staging environment. The output should be p50, p95, and p99 latency at peak load, error rate under load, and resource utilisation trends to confirm there are no resource leaks.
Database query performance under production data volumes is a specific performance concern that synthetic load tests can miss if the staging database does not have representative data. A query that runs in 5 milliseconds against 1,000 rows and in 8 seconds against 10 million rows is not a production-ready query. Missing indexes on columns used in WHERE clauses, ORDER BY clauses, or JOIN conditions are the most common cause of this pattern and are trivially detectable with a query execution plan review before go-live.
Operational Readiness: The Human Side of Going Live
A service can pass every technical checklist item and still produce a bad go-live experience if the human operational readiness has not been addressed. Operational readiness covers the people and process side of running a service in production, and it is the area most commonly treated as an afterthought by engineering teams focused on technical delivery.
On-call rotation and escalation paths must be defined before go-live, not after the first 3 AM incident surfaces the gap. The on-call engineer should know what they own, how to access the service’s runbooks, and who to escalate to when the runbook does not resolve the issue. This seems obvious and is consistently skipped in the rush to launch.
A rollback plan must exist and must be tested. The most common go-live failure mode is not a catastrophic outage. It is a subtle regression that becomes visible gradually after traffic ramps up, requiring a rollback that turns out to be slower and more complex than expected because it was never rehearsed. Blue-green deployments and feature flags both make rollback faster and lower risk. Knowing which one you are using and having tested the rollback path before go-live is a basic operational readiness requirement.
A launch communication plan covering who is notified when, what the traffic ramp schedule looks like, and what the criteria are for deciding to roll back versus continuing with a known issue, removes the ambiguity that causes bad decisions under pressure. Engineering managers who have been through a difficult go-live know that the decisions made in the first two hours of a production incident are often made worse by the absence of a pre-agreed framework for making them. Writing that framework down before launch costs one hour. Not having it can cost many more.
Prepare Your Engineering Team for Go-Live
Production Readiness Summary: Hard Gates vs Tracked Gaps
| Category | Hard Gate (must pass before go-live) | Tracked Gap (plan required) |
|---|---|---|
| Observability | Structured logs, golden signal metrics, alerting with runbooks | Custom business dashboards, advanced tracing depth |
| Security | Secrets in vault, input validation, auth on all endpoints | Penetration test, advanced threat modelling |
| Reliability | Timeouts, graceful shutdown, health checks, error boundaries | Full chaos engineering programme |
| Performance | Load test at peak traffic, slow query audit on prod data volumes | Full capacity planning model |
| Operations | On-call rotation, rollback plan tested, launch communication plan | Post-launch runbook expansion, game days |
Running the Checklist as an Engineering Process
The checklist is only as useful as the process that surrounds it. A production readiness review should happen at a defined point in the delivery timeline, early enough to address gaps without impacting the launch date and late enough that the service is stable enough to be meaningfully evaluated. Two to three weeks before intended go-live is a workable target for most services.
The review should be led by the tech lead for the service with participation from whoever is responsible for on-call, whoever owns the platform or infrastructure layer, and optionally a senior engineer from outside the team who can bring fresh eyes to the gaps. The output is a clear list of hard gate items that are not yet met, with owners and dates assigned to each one, and a list of tracked gaps with the same level of accountability. A production readiness review that produces a document no one reads is not a review. It is paperwork.
Tech leads who run this process consistently report that the value is not primarily in catching critical issues before launch, though that happens too. The primary value is in creating a shared understanding across the team of what the service looks like in production, who owns what, and where the known risks are. That shared understanding is what allows the team to respond effectively when something goes wrong, which it will. Production is where every assumption about your system gets tested against reality. The checklist is how you make sure as many of those assumptions as possible have already been tested before the traffic is real.
This discipline connects to the broader practice of building engineering systems that are correct by design rather than correct by luck. The same structured approach that makes backend language and infrastructure decisions more deliberate applies to the go-live process: the teams that think through the failure modes before they occur are consistently better at handling them when they do.
Most popular pages
-
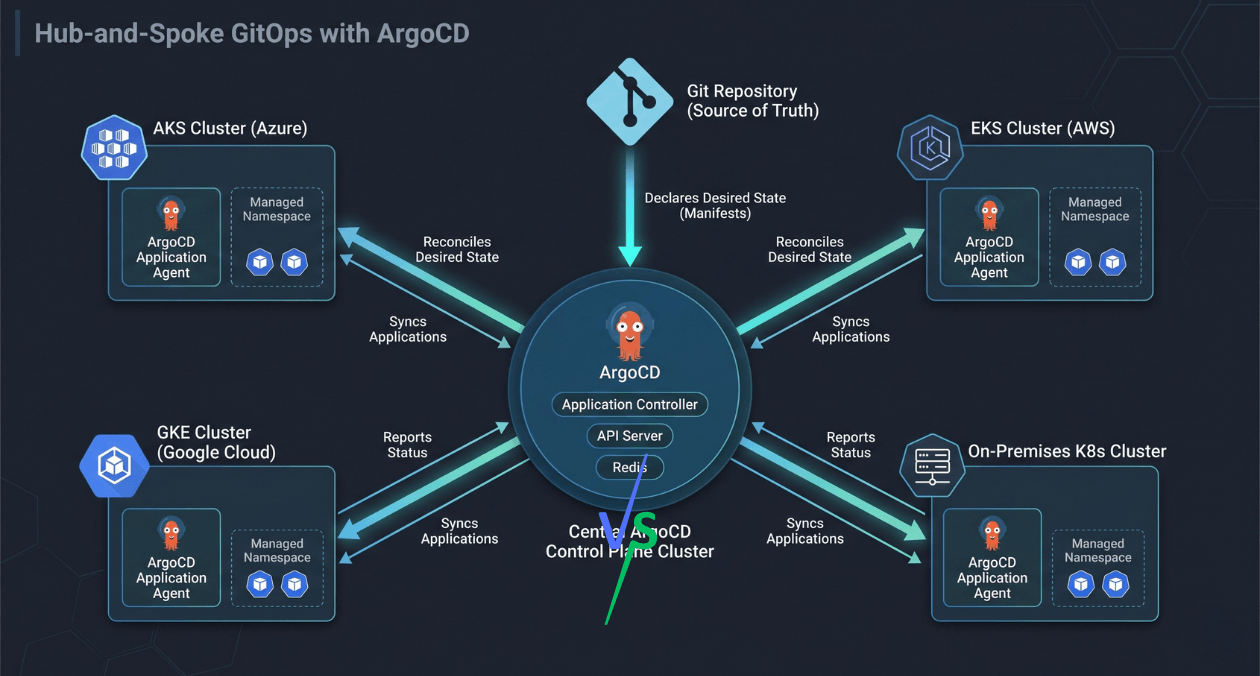
GitOps Beyond ArgoCD: Patterns That Scale for Large Engineering Organisations
ArgoCD became the default answer when someone said "GitOps" for a good few years. It solved the most common problem neatly: sync your Kubernetes...
-
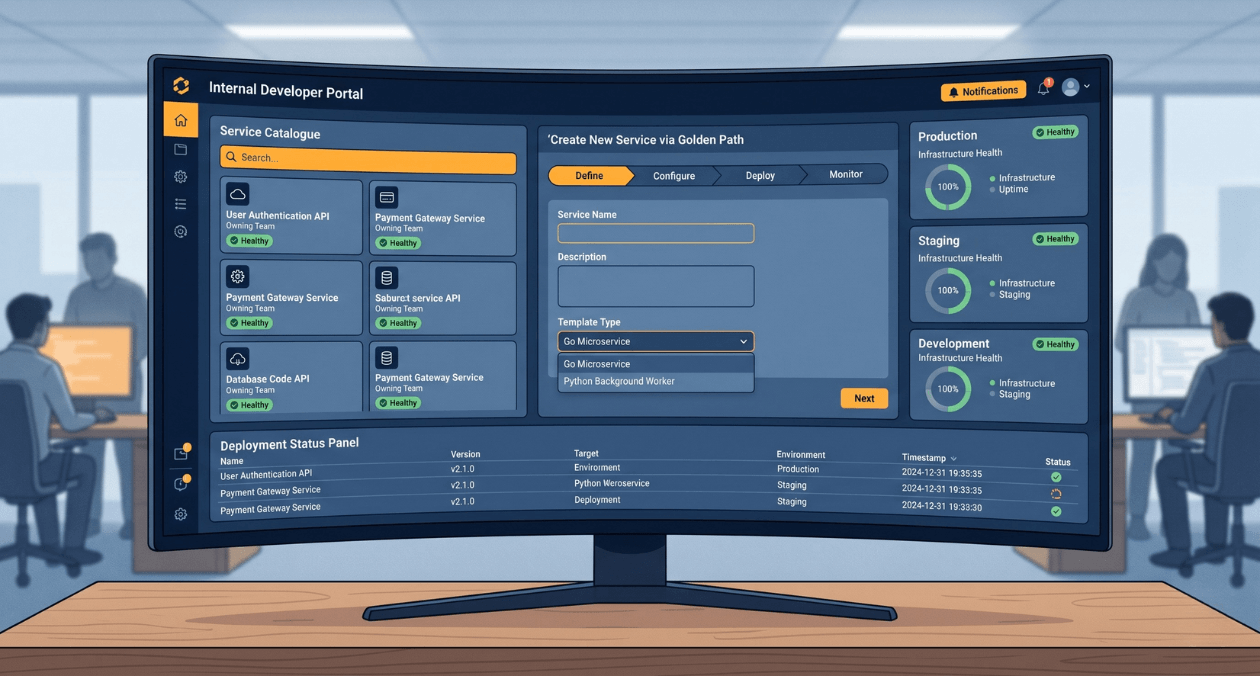
Building a Developer Experience (DX) Platform: From Golden Paths to Self-Service Infrastructure
There is a measurement problem at the heart of platform engineering. The people who benefit most from a well-built internal developer platform are often...
-
Search Infrastructure for Applications: Elasticsearch vs OpenSearch vs Typesense
Search is one of those features that seems straightforward until you try to build it properly. A basic LIKE query handles small datasets. The...
GitOps Beyond ArgoCD: Patterns That Scale for Large Engineering Organisations
ArgoCD became the default answer when someone said "GitOps" for a good few years. It solved the most common problem neatly: sync your Kubernetes...
Building a Developer Experience (DX) Platform: From Golden Paths to Self-Service Infrastructure
There is a measurement problem at the heart of platform engineering. The people who benefit most from a well-built internal developer platform are often...
Search Infrastructure for Applications: Elasticsearch vs OpenSearch vs Typesense
Search is one of those features that seems straightforward until you try to build it properly. A basic LIKE query handles small datasets. The...