



TABLE OF CONTENTS
Cost-Aware Engineering: Teaching Teams to Think About Resource Spend During Development

There is a gap inside most engineering organisations that rarely shows up in a sprint retrospective but shows up very clearly in quarterly cloud bills. Developers make dozens of technical decisions every week that carry real cost implications: which database tier to provision, how frequently a background job polls an external API, whether logs are shipped at DEBUG verbosity in production, how long data is retained in expensive hot storage before being moved to cheaper tiers. In most teams, those decisions are made without any visibility into their cost consequences. The engineer makes a reasonable technical choice, it ships to production, and the cost shows up weeks later in a finance report that nobody on the engineering team ever reads.
Cost-aware engineering is the practice of bringing resource spend into the development loop rather than treating it as a post-deployment concern. It is not about making engineers responsible for finance, and it is not about introducing bureaucratic approval gates on every infrastructure change. It is about giving developers the context and tooling they need to make better tradeoffs naturally, in the same moment they are making architectural and implementation decisions.
For engineering directors and CTOs, this is increasingly a strategic competency rather than a nice-to-have. As cloud infrastructure complexity grows and the range of pricing models across compute, storage, networking, and managed services expands, the cost surface of a modern application is genuinely difficult to reason about without deliberate practice. Teams that build cost awareness into their engineering culture ship features that are cheaper to run and are better positioned to scale without the bill scaling faster than the business.
Why the Default Culture Gets Cost Wrong
The default engineering culture treats infrastructure cost as an operations or finance problem. Developers provision resources to solve a technical problem. Operations teams monitor utilisation. Finance reviews the bill. If the bill is too high, someone eventually opens a cost optimisation project, engineers spend weeks retrofitting efficiency into code that was never designed with cost in mind, and the cycle repeats. This pattern is not the result of individual negligence. It is the result of an organisational structure that never surfaces cost information to the people who are in the best position to act on it.
The cloud pricing model makes this worse. In on-premise environments, hardware purchasing decisions were large, visible, and required sign-off. Cloud infrastructure can be provisioned in seconds by a developer with the right IAM permissions. The economic feedback loop has been severed from the technical decision loop. A developer can spin up an m5.4xlarge instance for a development environment, forget about it over a weekend, and return on Monday to find it has cost more than a month of a junior engineer’s productivity in compute hours. This is not a hypothetical. It is a routine occurrence in organisations that have not built cost visibility into their developer workflows.
FinOps as a discipline has emerged to address this gap at the organisational level, but FinOps practices that live entirely within a cloud finance team do not reach the engineers who write the code. The missing piece is bringing FinOps culture into the engineering workflow itself, not as a separate programme but as a natural extension of the technical practices teams already follow. The FinOps Foundation defines cost-aware engineering as a shared responsibility model where engineers, finance, and business stakeholders collaborate on cloud spend decisions rather than treating cost as a downstream concern.
The Cost Visibility Problem in Modern Engineering Teams
Before teams can act on cost, they need to see cost. This sounds obvious, but most engineering teams have surprisingly poor visibility into what their systems actually cost to run at the service or feature level. Cloud bills aggregate spending across an account or organisation in ways that make it difficult to attribute costs to specific services, teams, or features. An engineer who wants to know how much their microservice costs to run on a typical day cannot easily answer that question from a standard AWS Cost Explorer view without significant tagging discipline and cost allocation configuration.
Tagging is the foundation of cost visibility at the service level, and it is consistently the first thing that gets deprioritised in fast-moving teams. Every cloud resource should carry tags that identify the team, service, environment, and cost centre it belongs to. These tags are what allow cost reporting tools to break down cloud spend by the dimensions that matter to engineering teams: which service costs the most, which environment is running idle over weekends, which new feature launch correlated with a 40 percent increase in storage costs. Without tagging discipline, cost visibility efforts fail because the underlying data does not exist to build them on.
Beyond tagging, the tools available for engineering-level cost visibility have matured significantly. Cloud provider cost anomaly detection, Infracost for pull request cost estimation, and tools like Kubecost for Kubernetes workload cost attribution give engineering teams the ability to see the cost implications of their changes before they land in production. These tools are most effective when integrated into the development workflow, as pull request checks or pre-deployment gates, rather than reviewed as monthly reports after the spend has already occurred. This connects naturally to how mature teams are evolving their software development practices and tooling in 2025 and beyond.
Cost Visibility Tools by Engineering Context
| Tool / Approach | What It Addresses | Where It Fits |
|---|---|---|
| Resource tagging strategy | Cost attribution at service and team level | Cloud account governance, IaC templates |
| Infracost | Pull request cost delta estimates for IaC | CI/CD pipeline, pre-merge review |
| Kubecost | Per-workload cost attribution in Kubernetes | Platform team observability stack |
| Cloud cost anomaly detection | Unexpected spend spikes with alerting | Finance and engineering shared alerting |
| Unit cost metrics | Cost per request or transaction over time | Engineering dashboards, sprint reviews |
What Cost-Aware Engineering Looks Like in Practice
Cost awareness does not require engineers to become cloud billing experts. It requires that cost information is available at the moments when engineering decisions are being made, and that teams have a shared vocabulary for discussing cost tradeoffs alongside reliability, performance, and maintainability tradeoffs.
Cost in Architecture Reviews
The design review is one of the most valuable places to introduce cost conversation. When a team is evaluating whether to use a managed service or self-host, whether to use synchronous or asynchronous processing, or whether to replicate data across regions for availability, each of those choices carries a cost implication that can be estimated before any code is written. Adding a cost estimate section to architecture decision records (ADRs) normalises the expectation that engineers have considered the economic dimension of their design choices, not just the technical dimension.
This does not mean the cheapest option always wins. It means the cost of a technical choice is a visible input to the decision rather than an invisible consequence discovered later. A team that knowingly chooses a more expensive architecture because it reduces operational complexity or reduces time to market is making a better-informed decision than a team that chose the same architecture without considering the cost at all.
Cost as a Pull Request Concern
Bringing cost estimation into the pull request review cycle is one of the highest-leverage changes a team can make. Tools like Infracost parse Terraform and other IaC configurations and produce a cost delta estimate as a pull request comment, showing how a change affects estimated monthly spend before it merges. This is the same feedback loop model that static analysis and test coverage tools use to surface code quality signals during code review. Treating cost as another dimension of code quality, measured and visible during review, shifts cost conversations from reactive to proactive.
The cultural shift required here is modest. Engineers do not need training on cloud pricing models in detail. They need to see a number in their pull request that says this change adds an estimated 340 USD per month to production costs, and have a team norm that says changes above a threshold get a brief comment from a reviewer asking whether that delta was expected and intentional. That norm is enough to catch the majority of accidental cost regressions.
Build a Cost-Aware Engineering Culture
Unit Cost Metrics: The Bridge Between Engineering and Finance
One of the most effective tools for building shared understanding of cost between engineering and finance teams is the unit cost metric. A unit cost metric expresses infrastructure spend relative to a business metric: cost per active user, cost per API request, cost per transaction processed, cost per gigabyte of data stored and retrieved. These metrics translate the abstract language of cloud billing into business terms that both engineers and executives can reason about.
Unit cost metrics also create a natural feedback mechanism for cost efficiency work. If cost per transaction is tracked over time and displayed on an engineering dashboard alongside reliability and latency metrics, engineers can see whether their optimisation work is having the intended effect. A backend engineer who refactors a data access pattern to reduce database reads can see the cost per transaction metric improve over the following week. That visibility turns cost optimisation from an abstract finance exercise into a concrete engineering outcome, which makes it something engineers care about.
Building unit cost metrics requires the combination of spend data from your cloud provider with business metric data from your application instrumentation. This is not technically complex, but it does require deliberate effort to set up and maintain. The teams that sustain cost awareness culture over time are the ones that have made unit cost metrics a first-class citizen in their observability stack, visible in the same dashboards as latency percentiles and error rates rather than buried in a separate finance reporting tool.
Unit Cost Metrics by Application Type
| Application Type | Unit Cost Metric |
|---|---|
| SaaS product | Cost per active user per month |
| API platform | Cost per 1,000 API requests |
| Data pipeline | Cost per GB processed |
| E-commerce | Cost per transaction processed |
| ML inference service | Cost per model prediction |
| Storage-heavy application | Cost per GB stored (hot vs cold tier) |
Embedding Cost Awareness Into the Engineering Culture
Culture change is harder to ship than a new dashboard. The most durable cost awareness cultures are built on consistent habits rather than one-off initiatives. Several practices consistently work across different team types and organisation sizes.
Cost in Sprint Reviews and Team Metrics
Adding a brief cost update to sprint reviews, covering the week’s spend trend and any anomalies, normalises cost as a routine engineering concern rather than a crisis topic. This does not need to be a lengthy discussion. A two-minute summary of current unit cost metrics and whether they moved in the right or wrong direction is enough to keep cost visible without dominating engineering conversations. Over time, this habit creates a baseline expectation that engineers are aware of cost trends in their systems.
Environment Hygiene as a Cost Practice
Development and staging environments are a consistent source of unnecessary cloud spend in most organisations. Environments spun up for a feature branch that was merged three weeks ago, staging databases running at production scale for no clear reason, and test environments left running over long weekends and public holidays add up to a meaningful share of total cloud spend in active engineering teams. Automated environment teardown policies, scheduled shutdown of non-production resources outside working hours, and regular audits of orphaned resources are operational practices that engineering teams can own without any involvement from finance.
The Role of Platform Teams in Enabling Cost Awareness
Platform and infrastructure teams have a particularly important role in making cost awareness accessible to product engineers. When the internal developer platform exposes cost-efficient defaults, product engineers do not need to make cost-optimal choices actively. They need to deviate from the default, which creates a natural moment of friction that surfaces the cost conversation. Standardised compute tier recommendations, default auto-scaling policies that include scale-to-zero for non-critical workloads, and pre-configured cost alerting as part of every service template are platform-level decisions that embed cost efficiency into the development workflow without requiring individual engineers to manage it manually.
This is consistent with how leading engineering organisations are thinking about internal platform strategy. As explored in research from the DORA State of DevOps Report, teams with well-designed internal platforms report faster delivery and fewer reliability incidents. Cost-efficient defaults are a natural extension of that same platform thinking.
Cost-Aware Engineering Practices by Team Role
| Role | Key Cost-Aware Practice |
|---|---|
| Product engineer | Review Infracost delta on IaC pull requests |
| Tech lead | Include cost estimate in ADRs and design reviews |
| Platform engineer | Set cost-efficient defaults in service templates |
| Engineering manager | Track unit cost metrics in sprint reviews |
| Engineering director | Align cloud budget to product and team ownership |
| CTO | Champion FinOps culture as engineering competency |
Build a Cost-Aware Engineering Culture
Where Teams Get Cost-Aware Engineering Wrong
The failure mode most commonly seen in organisations attempting to build cost awareness is treating it as a finance initiative rather than an engineering initiative. When cost awareness is driven by a cloud cost team or a FinOps programme that sits outside engineering, it typically produces dashboards that nobody on the engineering team looks at and recommendations that arrive too late to influence technical decisions already made. Engineering buy-in requires that cost tooling lives where engineers already work: in their CI/CD pipeline, in their observability stack, in their pull request workflow.
The second failure mode is making cost the dominant concern rather than one of several. Engineering teams that are pressured to optimise costs at the expense of reliability, developer velocity, or maintainability make different kinds of mistakes. The goal is not the cheapest system. It is a system where cost is a conscious input to design decisions, the same way reliability and performance are conscious inputs. Teams that get this balance right ship systems that are good on all dimensions, not systems that are cheap and brittle.
A third failure mode is focusing cost awareness entirely on cloud compute and ignoring the cost of complexity. A microservices architecture with 40 services may have lower raw compute costs than a well-designed monolith, but the engineering time required to maintain, debug, and evolve that architecture carries a real cost that never appears on a cloud bill. Cost-aware engineering in its fullest form includes the cost of engineering time, not just the cost of infrastructure. This broader view connects naturally to how teams make architectural decisions, as discussed in Askan’s analysis of Flutter vs React Native performance and development speed tradeoffs, where the cost of developer time is as significant as the cost of runtime performance.
Getting Started: A Practical First Step for Engineering Leaders
For engineering directors and CTOs who want to move toward a cost-aware engineering culture, the most effective starting point is not a programme or an initiative. It is a measurement exercise. Pick the three most expensive services in your cloud bill and ask the engineering teams that own them to calculate a unit cost metric for each one. What does it cost to serve one active user for a month? What does it cost to process one transaction? What does it cost to run one background job?
This exercise almost always produces two outcomes. The first is that the teams involved learn something genuinely surprising about the cost profile of their systems. The second is that it creates a shared baseline that makes all subsequent cost conversations more concrete. Once a team knows that their service costs 0.4 USD per active user per month and the target is 0.25 USD, they have a clear engineering problem to work on rather than a vague mandate to reduce costs.
From that baseline, the next steps are to instrument unit cost metrics in your observability stack, add Infracost or an equivalent tool to your CI/CD pipeline for IaC changes, and introduce a standing cost update into your sprint review or team meeting cadence. None of these steps require significant investment. They require intent and consistency. The teams that sustain cost-aware engineering culture are not the ones with the most sophisticated tooling. They are the ones where engineering leaders have made cost visibility a consistent expectation rather than an occasional initiative.
Most popular pages
-
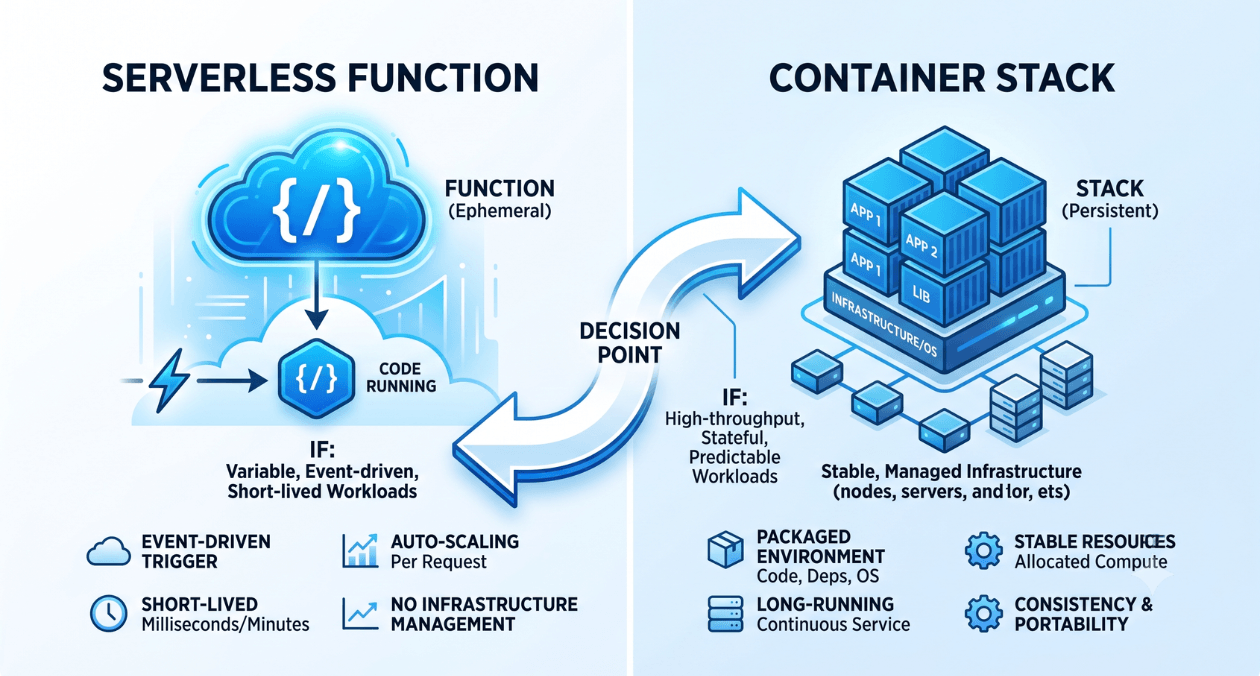
Serverless vs Containers: Choosing the Right Compute Model for Your Workload
Every engineering team building on the cloud eventually runs into this question: should this workload run on serverless functions or inside containers. The answer...
-
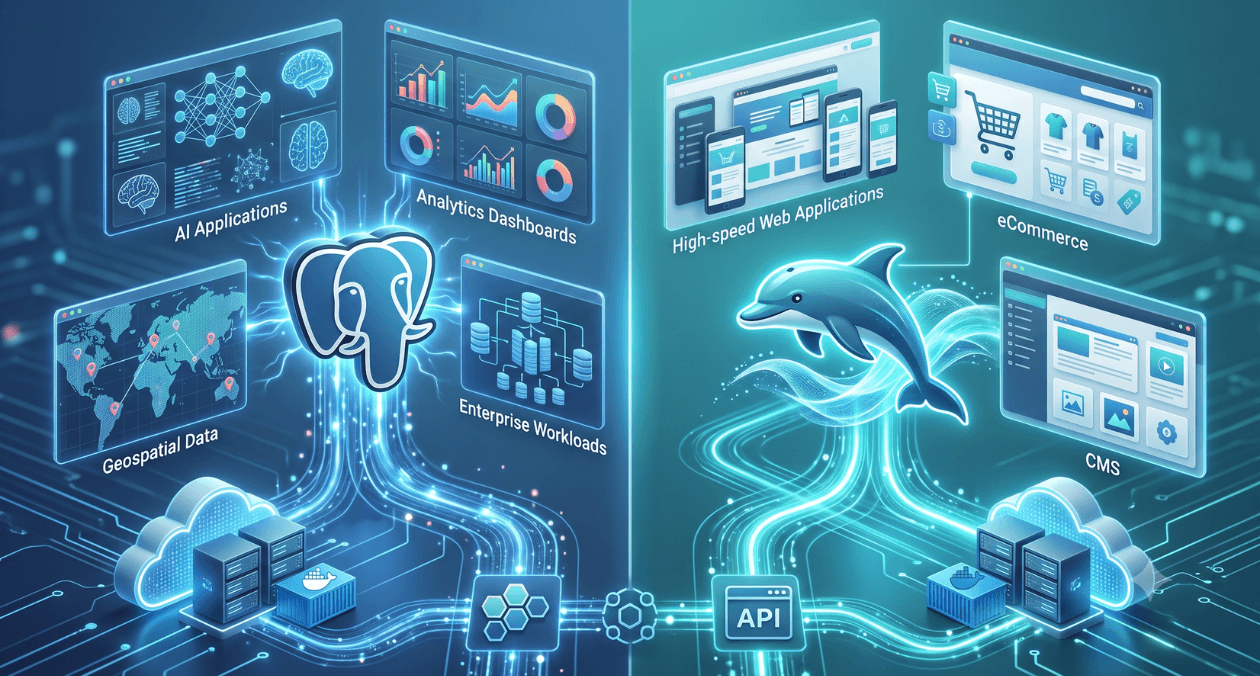
Postgres vs MySQL in 2026: Which Fits Modern Application Workloads Better
Every couple of years the Postgres versus MySQL debate resurfaces, and 2026 is no different. Teams building new applications still ask the same question...
-
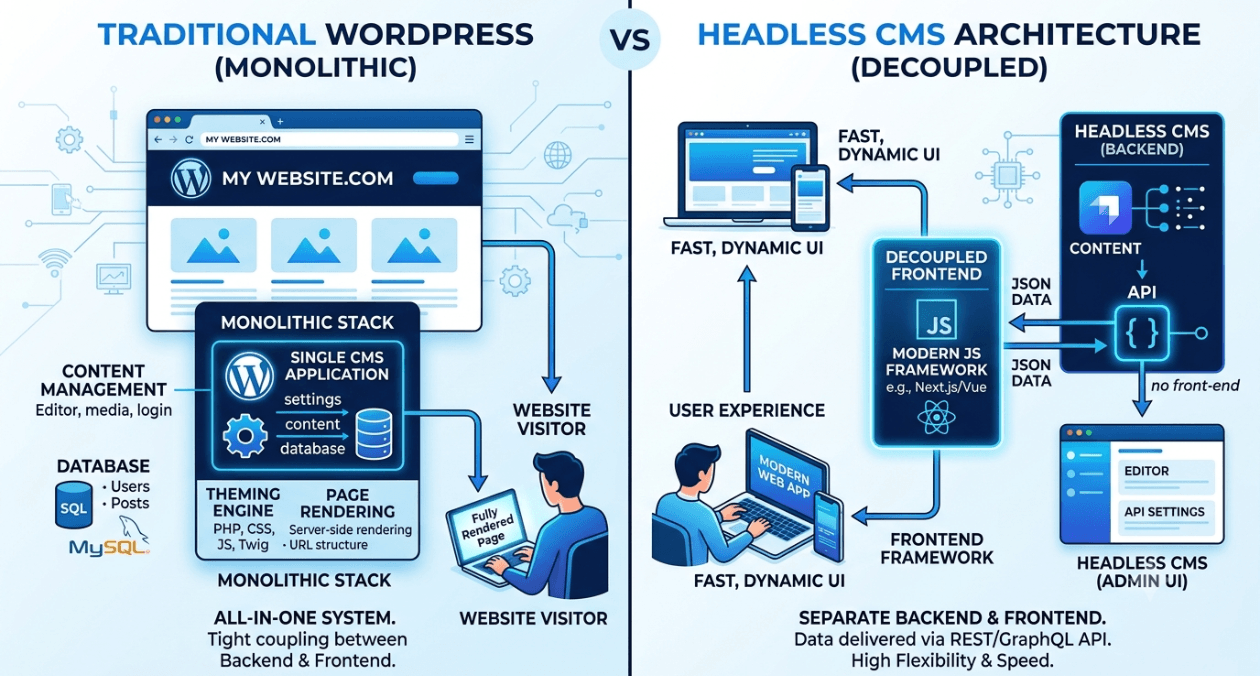
WordPress vs Headless WordPress: When Decoupling Actually Makes Sense
WordPress still runs a massive share of the web, and for good reason. It is fast to launch, familiar to content teams, and backed...
Serverless vs Containers: Choosing the Right Compute Model for Your Workload
Every engineering team building on the cloud eventually runs into this question: should this workload run on serverless functions or inside containers. The answer...
Postgres vs MySQL in 2026: Which Fits Modern Application Workloads Better
Every couple of years the Postgres versus MySQL debate resurfaces, and 2026 is no different. Teams building new applications still ask the same question...
WordPress vs Headless WordPress: When Decoupling Actually Makes Sense
WordPress still runs a massive share of the web, and for good reason. It is fast to launch, familiar to content teams, and backed...