



TABLE OF CONTENTS
LLM Integration in Production: Latency, Cost, and Reliability Patterns

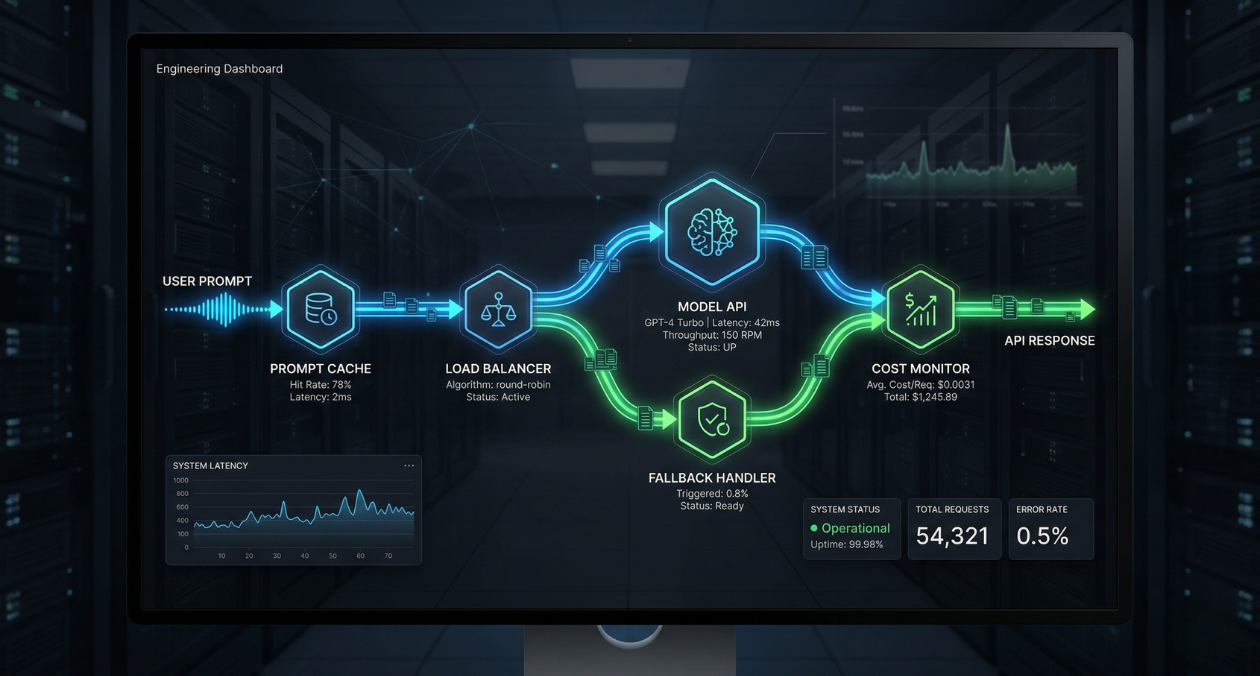
Integrating a large language model into a production system looked straightforward in 2023. Call the API, parse the response, ship it. Engineers who took that path and stayed on it have since learned, often through incidents and surprise billing statements, that production LLM integration is a distinct engineering discipline with its own failure modes, cost dynamics, and reliability patterns. The model being good is not sufficient. The system around it has to be engineered with the same rigor you bring to any latency-sensitive, high-availability service.
In 2026, the landscape is more complex than it was two years ago. The number of model providers has expanded. Pricing structures vary significantly across providers and model tiers. Prompt caching, streaming, token budgets, and fallback routing are now standard concerns for any team running LLMs in production. Engineering managers and AI engineers who treat LLM integration as a library call rather than an architectural surface are discovering this the hard way.
This deep dive covers the three dimensions that matter most: latency management, cost control, and reliability patterns. Each section describes the problem, the mechanisms behind it, and the engineering approaches that work in practice.
Understanding the LLM Latency Problem
Latency in LLM APIs is not like latency in a database query or a REST endpoint. A typical database read might take single-digit milliseconds. An LLM inference call to a frontier model routinely takes one to fifteen seconds depending on prompt length, model size, output length, and provider load. This is not a bug to be fixed. It is the physics of autoregressive token generation. Every token is generated sequentially, and longer outputs take proportionally longer.
The engineering challenge is that this latency profile interacts badly with user expectations and with the architectural assumptions of most web services. A 10-second wait on an API response is acceptable when the user is watching a streaming output appear word by word. It is not acceptable when the response is waiting to populate a UI component with no visible progress. The first design decision in any LLM integration is therefore not which model to use but how the response will be surfaced to the consumer.
Streaming vs Batch: The Foundational Choice
Streaming responses via server-sent events or WebSocket connections transform the user experience of LLM latency without changing the underlying model performance. The time-to-first-token, which typically ranges from 300 milliseconds to two seconds depending on provider and model tier, is what the user experiences as responsiveness. Everything after that is visible progress rather than an unexplained wait. For any product surface where the LLM output is read by a human, streaming is the right default.
Batch processing is the right pattern when the output feeds a downstream pipeline rather than a human. Document classification, structured extraction, bulk summarization, and data enrichment workflows should use batch APIs where available. OpenAI’s Batch API and Anthropic’s message batches endpoint both offer significantly lower per-token pricing in exchange for relaxed SLA windows, typically 24 hours. For workloads that do not require real-time responses, this price differential is meaningful at scale.
Prompt Caching: The Most Underused Latency and Cost Lever
Prompt caching is one of the most impactful techniques available for production LLM systems and one of the least consistently applied. The mechanism is straightforward: when a significant portion of your prompt is static across requests, the model provider can cache the processed representation of that static portion and skip reprocessing it on subsequent calls. This reduces both latency and cost, since cached tokens are priced at a fraction of input token rates.
The practical implication is that prompt design should be cache-aware. Static content, system instructions, reference documents, few-shot examples, and schema definitions should be positioned at the beginning of the prompt where they are most likely to be cached. Dynamic content such as the user query or the current conversation turn should come at the end. This is a simple structural change that can reduce inference costs by 50 to 90 percent for applications with long, repetitive system prompts.
Anthropic’s prompt caching feature for Claude models and OpenAI’s equivalent both require explicit cache breakpoint markers or use structural patterns that the provider detects automatically. Engineers should verify that their prompts are structured to maximize cache hit rates and monitor cache hit ratios in production to detect regressions when prompt templates change. According to Anthropic’s documentation on prompt caching, cache writes are priced at 25 percent above standard input token rates while cache reads come in at 10 percent of the base rate, making high cache hit ratios economically significant at any meaningful call volume.
Prompt Caching: Cost Impact at Scale
| Scenario | Cost Impact |
|---|---|
| No caching, 2000-token system prompt, 10k calls/day | Full input token cost on every call |
| 80% cache hit rate, same volume | Roughly 70% reduction in input token costs |
| 100-token dynamic suffix, 1900-token cached prefix | Only 100 tokens billed at full rate per cached call |
| Cache miss after prompt template change | Full reprocessing cost until cache warms up again |
Cost Control in Production: Beyond Token Counting
Token counting is the entry point of LLM cost management, not the destination. Teams that have been running LLMs in production for more than six months discover that the real cost drivers are prompt engineering decisions, model tier selection, output length control, and the absence of guardrails on what triggers model calls at all.
Model tier selection deserves more architectural attention than it typically receives. Frontier models like GPT-4o and Claude Opus are significantly more expensive per token than smaller models in the same families. Many production tasks do not require frontier model capability. Intent classification, short summarization, structured extraction from well-formatted input, and simple question answering over constrained domains can often be handled by smaller, cheaper models with acceptable quality. A tiered routing architecture that sends simple tasks to cheaper models and complex tasks to frontier models can reduce overall inference costs substantially without degrading user-facing quality.
Output length is another underappreciated cost lever. LLM providers charge for both input and output tokens, but output tokens are typically priced higher than input tokens. Prompts that do not constrain output length will produce variable-length responses, and models tend toward verbosity when unconstrained. Explicit output length instructions in the system prompt, combined with max_tokens parameters, bring output costs under control and often improve response quality by reducing padding and repetition.
Routing and Model Selection Strategy
A production LLM integration should treat model selection as a runtime decision, not a configuration constant. The routing logic can be simple or sophisticated depending on your use case, but even a basic implementation that distinguishes between simple and complex requests and routes them to different model tiers produces measurable cost reductions. More advanced approaches use a small, fast classifier to score request complexity and route accordingly, or use a cascade pattern where a cheap model attempts the task first and a more expensive model is only invoked if the initial response fails a quality threshold.
This architectural thinking is consistent with how mature engineering teams approach other tiered resource decisions. The software development technology trends shaping engineering in 2025 illustrates how similar cost-aware architecture thinking is being applied across the stack, from model selection to infrastructure provisioning.
Building LLM-Powered Products?
Reliability Patterns for Production LLM Services
LLM APIs are external dependencies with their own availability profiles, rate limits, and failure modes. Treating them as reliable infrastructure rather than unreliable external services is one of the most common sources of production incidents in AI-powered applications. The reliability engineering work required to run LLMs safely in production maps closely to the patterns used for any high-value external API, but with some additional considerations specific to the latency and output characteristics of inference calls.
Retry Logic and Exponential Backoff
Rate limit errors and transient server errors from LLM providers are common at production scale. Every LLM client library should implement exponential backoff with jitter on retries, with different backoff profiles for rate limit errors versus server errors. Rate limit errors warrant longer backoff windows since the token bucket needs time to refill. Server errors can use shorter windows since they are typically transient. Retrying without backoff under rate limiting conditions makes the problem worse and can trigger provider-side circuit breaking.
Request timeouts are equally important. LLM calls can hang for extended periods under provider load. Without a client-side timeout, a small number of slow requests can exhaust connection pools and degrade the entire service. Set a timeout that reflects your latency SLA plus a reasonable buffer, and handle timeout errors explicitly in your fallback logic rather than propagating them as generic 500 errors to your upstream consumers.
Fallback and Multi-Provider Routing
Single-provider LLM integrations create a hard dependency on that provider’s availability. Teams running business-critical features on LLMs should have a fallback provider configured and tested. The practical implementation involves abstracting the LLM call behind a provider-agnostic interface, maintaining a primary provider and one or more fallback providers, and implementing health checks or circuit breakers that detect provider degradation and route traffic accordingly.
Multi-provider routing also enables cost optimization through provider-level arbitrage. Different providers price similar capability differently at different times, and workloads that are not latency-critical can be routed to whichever provider offers the best cost-quality tradeoff at a given moment. This is a more advanced pattern but is increasingly common in organizations running significant LLM inference volumes.
Common LLM Production Failure Modes and Mitigations
| Failure Mode | Root Cause | Mitigation |
|---|---|---|
| Rate limit errors spike | Burst traffic without token bucket management | Implement client-side rate limiting and queue |
| Timeout-induced latency spikes | No client timeout configured | Set aggressive per-request timeout, handle gracefully |
| Cost overrun from verbose outputs | No max_tokens or output length instruction | Constrain output length in prompt and params |
| Cache miss rate regression | Prompt template change invalidates cache | Monitor cache hit ratio, test prompt changes in staging |
| Provider outage cascades | Single provider dependency | Implement fallback provider with circuit breaker |
| Hallucination in structured output | No output validation layer | Schema validation plus retry on parse failure |
Observability: What You Need to Measure
An LLM integration without observability is an integration you cannot improve or debug in production. The standard APM metrics of latency, error rate, and throughput are necessary but not sufficient. LLM-specific metrics that engineering teams should instrument from day one include time-to-first-token, total generation time, prompt token count, completion token count, cache hit ratio, model tier distribution (if using routing), and cost per request. These metrics tell a fundamentally different story than generic latency numbers and are essential for understanding the behavior of the system over time.
Prompt logging with appropriate data governance is also important. The ability to replay production prompts and responses in a testing environment makes debugging quality regressions dramatically faster. Most teams that skip prompt logging regret it the first time they encounter a quality issue they cannot reproduce. The governance consideration is that prompts often contain user data, so logging pipelines need appropriate access controls, retention policies, and anonymization where required.
Cost attribution at the request level enables the unit economics analysis that drives intelligent optimization decisions. Tracking which features, user segments, or request types are responsible for what share of inference costs gives engineering managers the data needed to prioritize optimization work. Without it, cost reduction efforts tend to be applied broadly and inefficiently rather than targeted at the highest-impact workloads.
Output Validation and Structured Generation
Production LLM integrations that return free text to downstream systems without validation are one incident away from a bad day. Models can return malformed JSON, truncated outputs, or content that fails schema constraints even when instructed explicitly. The right pattern is to treat LLM output as untrusted external input that requires validation before use, exactly as you would treat input from any external API.
Structured output modes, now available from most major providers, constrain the model to return output that conforms to a specified JSON schema. This dramatically reduces parse failure rates but does not eliminate them entirely. The recommended pattern is schema validation on every response with a retry on failure, a maximum retry count to prevent infinite loops, and a graceful degradation path for cases where valid structured output cannot be obtained. This retry-on-invalid pattern should be instrumented so that high parse failure rates are visible in your observability stack, since they often indicate prompt quality issues or model selection mismatches.
LLM Integration Patterns: Quick Reference
| Pattern | Addresses | When to Apply |
|---|---|---|
| Prompt caching | Latency and cost on repeated prefixes | Any app with long static system prompts |
| Streaming responses | Perceived latency for human consumers | All user-facing generation surfaces |
| Model tier routing | Cost reduction without quality loss | Mixed complexity workloads |
| Batch API | Cost on non-real-time workloads | Pipelines, enrichment, classification at scale |
| Multi-provider fallback | Reliability and provider availability | Business-critical LLM features |
| Output schema validation | Reliability of structured outputs | Any structured data extraction use case |
Building LLM-Powered Products?
Putting It Together: A Production-Ready Integration Architecture
A production-ready LLM integration is not a single API call. It is a small system with its own components, failure boundaries, and operational concerns. The core components of a mature integration include a prompt management layer that handles template versioning, caching structure, and token budget enforcement; a routing layer that selects model tier and provider based on request characteristics and current provider health; an inference client with retry logic, timeout handling, and streaming support; an output validation layer with schema enforcement and retry-on-failure; and an observability layer that emits the LLM-specific metrics described above.
None of these components are architecturally complex. Each one is a well-understood engineering pattern applied to the specific characteristics of LLM APIs. The discipline is building all of them before you need them rather than after your first production incident teaches you why they exist. Teams that start with a minimal integration and add these components incrementally tend to build more reliable systems than teams that attempt to build the complete architecture up front without production feedback.
The integration patterns that work for LLMs share structural similarities with other distributed system reliability concerns. The circuit breaker, fallback, and retry patterns described here map directly to the broader reliability engineering thinking covered in resources like Martin Fowler’s patterns of enterprise application architecture, which remains one of the most useful references for engineers designing systems with external dependencies.
As LLM capabilities continue to evolve and inference costs continue to fall, the engineering discipline around production integration is becoming a genuine differentiator. The teams that build robust, observable, cost-efficient LLM systems today are accumulating institutional knowledge and operational experience that will compound as the technology matures. The patterns in this article are not temporary workarounds. They are the foundations of a production engineering practice for AI-powered systems that will remain relevant as the underlying models improve.
Most popular pages
-

Prompt Injection and LLM Security: What Engineering Teams Must Defend Against
Every LLM powered feature shipped in the last two years shares one uncomfortable trait: the model reads instructions and data through the same channel....
-

Building Internal Developer Platforms: Lessons from Teams That Got It Right
Every engineering org eventually hits the same wall. Deployment steps live in five different runbooks, onboarding a new developer takes three weeks of Slack...
-

AMP for Ecommerce in 2026: Is It Still Worth Implementing?
For a few years, AMP was the fastest route to a spot in Google's mobile carousel, and ecommerce teams built entire template libraries around...
Prompt Injection and LLM Security: What Engineering Teams Must Defend Against
Every LLM powered feature shipped in the last two years shares one uncomfortable trait: the model reads instructions and data through the same channel....
Building Internal Developer Platforms: Lessons from Teams That Got It Right
Every engineering org eventually hits the same wall. Deployment steps live in five different runbooks, onboarding a new developer takes three weeks of Slack...
AMP for Ecommerce in 2026: Is It Still Worth Implementing?
For a few years, AMP was the fastest route to a spot in Google's mobile carousel, and ecommerce teams built entire template libraries around...