



TABLE OF CONTENTS
Data Warehouse vs Data Lake vs Data Lakehouse: Analytics Infrastructure for 2026


Every organization that generates data eventually faces a version of the same question: where should that data live so that the people and systems that need it can access it reliably, quickly, and without paying engineers to move it around constantly? The answer has changed significantly over the past fifteen years, and in 2026 it is changing again.
The data warehouse emerged from a world where business intelligence meant scheduled reports, and analysts needed clean, structured data that had been carefully prepared for their queries. The data lake emerged from a world where machine learning and big data processing required raw, unstructured data at a scale and variety that warehouses could not store economically. The data lakehouse emerged from the recognition that neither the warehouse nor the lake fully solved the problem alone, and that the industry needed an architecture that combined the governance and performance of the warehouse with the openness and flexibility of the lake.
This guide provides a precise technical breakdown of all three architectures, the platforms that implement each one, how they compare across the dimensions that matter most for analytics infrastructure decisions in 2026, and the decision framework that data architects, analytics directors, and CTOs use to select and evolve their analytics stack.
The Business Pressure Driving Analytics Infrastructure Decisions
Analytics infrastructure decisions are rarely purely technical. They are shaped by the speed at which business units want answers, the diversity of data types the organization generates, the skills of the team maintaining the infrastructure, and the budget available for storage and compute. Understanding these pressures before evaluating specific architectures produces better outcomes than evaluating architectures in isolation from the organizational context they will operate in.
Three business pressures define the analytics infrastructure landscape in 2026. The first is AI and machine learning integration: every major analytics platform now provides native integration with machine learning frameworks, and organizations that separate their ML training data from their analytics data pay a significant duplication and consistency tax. The second is real-time analytics: batch reporting cycles that satisfied leadership dashboards five years ago are increasingly inadequate as organizations want to respond to events as they happen. The third is data governance and compliance: regulations like GDPR, HIPAA, and CCPA impose data residency, access control, and deletion requirements that analytics infrastructure must enforce, not merely tolerate.
| Business Pressure | Analytics Infrastructure Implication |
|---|---|
| AI and ML model training | Raw data must be accessible alongside structured analytics data; unified storage preferred |
| Real-time decision making | Streaming ingestion and sub-second query latency required alongside batch analytics |
| Data governance and compliance | Column-level access controls, audit logging, and data lineage tracking are infrastructure requirements |
| Cost optimization | Compute and storage separation allows scaling each independently; cold storage tiers reduce cost |
| Self-service analytics | Business analysts need governed access to data without engineering bottlenecks on every query |
The Data Warehouse: Structured Analytics at Governed Scale
Architecture and Design Philosophy
A data warehouse is a subject-oriented, integrated, non-volatile, and time-variant collection of data designed specifically to support business intelligence and analytical queries. Bill Inmon’s four-part definition from 1990 remains accurate in 2026, even though the implementation technology has changed dramatically from the on-premise MPP appliances of the 2000s to the cloud-native columnar warehouses of today.
Data enters the warehouse through an ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) pipeline that cleanses, validates, and transforms raw source data into a structured schema before it is available for querying. The schema is enforced on write: data that does not conform to the defined structure is rejected at ingestion. This schema-on-write model is the central trade-off of the warehouse: it requires upfront schema design and transformation work, but it guarantees that every analyst querying the warehouse sees clean, consistent, trustworthy data.
Modern cloud data warehouses store data in a columnar format rather than row-based format. Columnar storage physically groups all values of the same column together on disk, rather than grouping all columns of the same row together. An analytical query that aggregates revenue across ten million rows needs only the revenue and date columns. Columnar storage reads only those two columns from disk, skipping all other columns entirely. On a table with fifty columns, this selective reading can reduce I/O by 96 percent compared to a row-based format, which is why columnar warehouses achieve dramatic query performance improvements for analytical workloads.
Leading Cloud Data Warehouse Platforms
| Platform | Key Architecture Characteristic | Best Fit |
|---|---|---|
| Snowflake | Multi-cluster, compute/storage separation, zero-copy cloning, time travel |
Multi-cloud organizations wanting managed warehouse with rich sharing features |
| Google BigQuery | Serverless, no cluster management, built-in ML (BigQuery ML), streaming inserts |
GCP-native teams and organizations wanting zero infrastructure management |
| Amazon Redshift | Massively parallel processing, RA3 node compute/storage separation, Redshift Spectrum for S3 | AWS-native organizations with existing Redshift workloads or Spectrum access needs |
| Azure Synapse Analytics | Unified workspace: Spark, SQL pool, Pipelines, Power BI integration |
Microsoft Azure environments needing unified analytics and data integration |
| Databricks SQL Warehouse | Lakehouse approach, Delta Lake storage, serverless SQL endpoint |
Teams already on Databricks platform wanting SQL analytics layer |
Data Modeling in the Warehouse: Star and Snowflake Schemas
Dimensional modeling is the standard schema design approach for analytical workloads in a data warehouse. Ralph Kimball’s dimensional modeling methodology structures data into fact tables and dimension tables. Fact tables contain measurements and metrics: revenue, quantity, duration. Dimension tables contain descriptive attributes: customer name, product category, geographic region, date components. A query joining fact tables to dimension tables is expressed simply in SQL and executes efficiently because the columnar format minimizes I/O for each dimension used.
The star schema places denormalized dimension tables directly around the central fact table, minimizing the number of joins required for typical queries. The snowflake schema normalizes dimension tables further into sub-dimension tables, reducing storage redundancy at the cost of additional joins. For most analytical workloads, the star schema’s query simplicity and performance advantages outweigh the snowflake schema’s storage efficiency, which is why star schemas remain the dominant production approach despite the theoretical elegance of further normalization.
| Schema Type | Characteristics |
|---|---|
| Star schema | Denormalized dimensions, fewer joins, faster queries, more storage |
| Snowflake schema | Normalized dimensions, more joins, slower queries, less storage |
| One Big Table (OBT) | Fully pre-joined and denormalized, fastest queries, highest storage, used for specific high-volume reporting tables |
Where Data Warehouses Excel and Where They Struggle
Data warehouses are the right choice when governance, query performance on structured data, and BI tool integration are the primary requirements. A finance team that needs monthly revenue reconciliation reports with auditable data lineage, a marketing team running customer segmentation queries against a hundred million user records, and a product team building self-service dashboards for non-technical stakeholders are all natural warehouse users.
Where warehouses struggle is with data variety and cost at extreme scale. Storing raw unstructured data, log files, images, audio, video, and semi-structured JSON events, in a data warehouse is either technically impractical or prohibitively expensive. The transformation work required to ingest data into a structured warehouse schema creates pipeline latency that makes near-real-time analytics difficult. And the proprietary storage format of most warehouses creates vendor lock-in that becomes painful when organizations want to run ML workloads on the same data outside the warehouse ecosystem.
Architect Your Analytics Infrastructure
The Data Lake: Raw Storage for Every Data Type
Origin and Core Concept
The data lake concept emerged from the intersection of two forces: the arrival of Hadoop and distributed file systems that made storing petabytes of data economically viable, and the recognition by data science and machine learning teams that the transformation work required to load data into a warehouse was discarding precisely the raw signal that ML models needed. James Dixon, who coined the term data lake in 2010, contrasted it with the data mart (a subset of the warehouse): a data mart is like a bottle of water, cleaned, packaged, and structured for a specific purpose; a data lake is a large body of water in a more natural state, where various consumers take the water in whatever form they need it.
A data lake stores data in its raw, original form in a flat storage hierarchy, typically an object store like Amazon S3, Google Cloud Storage, or Azure Data Lake Storage. There is no schema enforcement at write time. Data is written as files in whatever format the source produces: CSV, JSON, Parquet, ORC, Avro, images, logs, audio. The schema is applied at read time by the query engine, a model called schema-on-read. This defers the cost and constraint of schema definition until there is a specific analytical purpose, preserving the full fidelity of the raw data indefinitely.
The Medallion Architecture: Organizing the Data Lake
A raw data lake without organizational structure quickly becomes a data swamp: vast quantities of data that are technically present but practically inaccessible because no one knows where specific data is, what format it is in, or whether it has been cleaned. The medallion architecture provides a three-tier organizational structure that is now the standard approach for data lake organization.
| Layer | Content | Consumers |
|---|---|---|
| Bronze (Raw) | Exact copy of source data in original format; append-only, never modified |
Data engineers debugging pipeline issues; ML teams needing raw signal |
| Silver (Cleaned) | Validated, deduplicated, type-corrected data in Parquet or ORC format; schema enforced |
Data scientists, ML feature engineering, intermediate transformations |
| Gold (Curated) | Business-level aggregations, denormalized views, KPI tables ready for analytics consumption |
Business analysts, BI dashboards, executive reporting |
The bronze layer is immutable. Data is never deleted or corrected in the bronze layer; if an upstream system sends corrupted data, the correction is applied in the silver layer transformation, and the original corrupted data is preserved in bronze for audit purposes. This immutability is what gives the data lake its replay capability: any silver or gold transformation can be recomputed from scratch by reprocessing the bronze data through updated transformation logic.
Data Lake Limitations That Led to the Lakehouse
Data lakes solved the storage cost and data variety problems but introduced a new set of operational challenges that became increasingly painful as data lakes grew in scale and organizational importance.
| Data Lake Limitation | Operational Impact |
|---|---|
| No ACID transactions on object storage | Concurrent writes produce partial reads; failed writes leave corrupt partial files |
| No schema enforcement at write time | Schema drift: different pipeline versions write incompatible schemas silently |
| No data versioning or time travel | Accidental overwrites or deletes are unrecoverable without separate backup infrastructure |
| No query performance optimization | Every query scans files without statistics; performance degrades as data volume grows |
| Difficult BI tool integration | Most BI tools expect a SQL interface with metadata; direct S3 access requires additional layers |
| Data governance complexity | No native column-level access control, audit logging, or data lineage on raw object storage |
The Data Lakehouse: Unified Analytics Architecture
What the Lakehouse Architecture Solves
The data lakehouse is an architecture that adds a structured metadata and transaction layer on top of open-format files stored in a data lake, providing ACID transactions, schema enforcement, query optimization, and BI tool compatibility without copying data into a proprietary warehouse format. The term was introduced by Databricks and formalized in a 2021 research paper, though the underlying concept had been taking shape through open table formats like Delta Lake, Apache Iceberg, and Apache Hudi.
The central insight of the lakehouse is that the limitations of the data lake were not inherent to object storage. They were caused by the absence of a metadata layer that tracked table structure, file statistics, and transaction state. By adding that metadata layer on top of standard Parquet files stored in S3 or GCS, the lakehouse delivers warehouse-grade query performance, ACID reliability, and governance capability while keeping data in an open format that any compatible engine can read without vendor lock-in.
Open Table Formats: The Technical Foundation of the Lakehouse
Three open table formats define the lakehouse landscape: Delta Lake, Apache Iceberg, and Apache Hudi. Each adds a metadata layer on top of Parquet files that enables ACID transactions, schema evolution, time travel, and query optimization. They are not storage formats themselves; they are metadata specifications that any compatible query engine can implement support for.
| Table Format | Origin | Key Differentiator |
|---|---|---|
| Delta Lake | Databricks (open-sourced) | Transaction log as JSON files in _delta_log directory; deep Spark integration; Change Data Feed for incremental processing |
| Apache Iceberg | Netflix and Apple (donated to Apache) | Manifest-based metadata; engine-agnostic design; excellent partition evolution; hidden partitioning |
| Apache Hudi | Uber (open-sourced) | Optimized for upsert and incremental processing; record-level indexing; near-real-time data freshness |
Apache Iceberg has seen the strongest adoption momentum in 2026, driven by its engine-agnostic design that allows Spark, Trino, Flink, Presto, Snowflake, BigQuery, and Redshift to all read and write the same Iceberg tables without format conversion. The Iceberg REST Catalog specification standardizes how query engines discover table metadata, reducing integration complexity when multiple engines need to access the same tables.
Delta Lake’s strength is its deep integration with the Databricks platform and its Change Data Feed feature, which exposes row-level changes as a consumable stream. This makes Delta Lake particularly effective for incremental processing pipelines where downstream systems need to process only the rows that changed since the last run, rather than reprocessing the entire table.
Time Travel and Data Versioning
One of the most operationally valuable features of lakehouse table formats is time travel: the ability to query a table as it existed at a previous point in time. Delta Lake maintains a transaction log that records every write operation. A query with AS OF TIMESTAMP ‘2026-03-20 09:00:00’ or VERSION AS OF 142 reads the version of the table that existed at that timestamp or version number, with no separate backup infrastructure required.
Time travel compresses the distance between data quality incidents and recovery. When a pipeline bug writes incorrect data to a gold layer table, the recovery procedure is to identify the last known-good version, run RESTORE TABLE to that version, and replay the corrected transformation. Operations that previously required restoring from a backup, a multi-hour process, become a single SQL command that completes in seconds by updating the transaction log pointer to the previous version without moving any data files.
Leading Lakehouse Platforms
| Platform | Table Format | Best Fit |
|---|---|---|
| Databricks | Delta Lake (native), Iceberg and Hudi supported |
Organizations wanting unified data engineering and ML platform |
| Apache Spark + Iceberg | Apache Iceberg | Open-source, engine-agnostic lakehouse without vendor lock-in |
| AWS Lake Formation + Athena | Iceberg or Hudi on S3 | AWS-native lakehouse with serverless SQL and fine-grained access control |
| Snowflake Open Catalog | Apache Iceberg (Polaris Catalog) | Organizations using Snowflake for warehouse wanting to extend to external Iceberg tables |
| Google BigLake | Iceberg on GCS | GCP-native lakehouse with BigQuery governance applied to external data |
| Microsoft Fabric | Delta Lake (OneLake) | Microsoft ecosystem consolidation: Azure, Power BI, Synapse in one platform |
Architect Your Analytics Infrastructure
Head-to-Head: Warehouse vs Lake vs Lakehouse
Core Architecture Comparison
| Dimension | Data Warehouse | Data Lake |
|---|---|---|
| Storage format | Proprietary columnar (vendor-specific) |
Open formats: Parquet, ORC, Avro, CSV, JSON |
| Schema model | Schema-on-write: enforced at ingestion |
Schema-on-read: applied at query time |
| ACID transactions | Full ACID natively | None natively on object storage |
| Data types supported | Structured and semi-structured (JSON) |
All types: structured, semi-structured, unstructured |
| Query performance | Excellent on structured analytics queries |
Variable; depends on file size, format, and partitioning |
| ML and AI workloads | Limited; data must be exported for training |
Native; data scientists access raw data directly |
| Storage cost at scale | High (proprietary compute+storage) | Low (commodity object storage) |
| Vendor lock-in risk | High (proprietary format) | Low (open formats) |
| Dimension | Data Lakehouse |
|---|---|
| Storage format | Open formats (Parquet) with metadata layer (Delta Lake, Iceberg, Hudi) |
| Schema model | Schema-on-write enforced by table format metadata layer |
| ACID transactions | Full ACID through table format transaction log |
| Data types supported | All types; structured and unstructured in same storage tier |
| Query performance | Warehouse-grade with partition pruning, file statistics, Z-ordering |
| ML and AI workloads | Native; same storage layer serves both analytics and ML training |
| Storage cost at scale | Low to moderate (object storage + compute separation) |
| Vendor lock-in risk | Low (open table formats readable by multiple engines) |
Query Performance Comparison
Raw data lake query performance on unoptimized Parquet files can be orders of magnitude slower than a well-tuned data warehouse on the same data. The warehouse’s internal statistics, sorted storage, and pre-built indexes allow its query planner to skip irrelevant data precisely. A query planner that does not know how many rows match a filter condition must scan everything.
The lakehouse closes this gap through several mechanisms. Table statistics maintained in the metadata layer give query planners the row counts, min/max values, and null counts they need for accurate selectivity estimation. Partition pruning skips partitions that cannot contain rows matching the filter condition. Z-ordering (data skipping) in Delta Lake and clustering in Iceberg physically co-locate related rows within data files, allowing file-level statistics to skip entire files rather than scanning them. Bloom filters in Iceberg and Hudi provide probabilistic skip logic for high-cardinality columns used in point lookups.
| Optimization Technique | How It Works | Impact |
|---|---|---|
| Partition pruning | Query planner skips partitions outside the filter range |
Reduces data scanned from 100% to a small partition subset |
| File statistics (min/max) | Query planner skips files whose min/max range excludes the filter value |
Reduces file reads for range queries on sorted columns |
| Z-ordering / clustering | Co-locates related rows within files based on frequently filtered columns |
Reduces files read for multi-column filter queries |
| Bloom filters | Probabilistic structure that quickly determines if a value exists in a file |
Accelerates point lookups on high-cardinality columns |
| Compaction (OPTIMIZE) | Merges small files into large files; improves read parallelism and scan speed |
Eliminates small file problem that degrades streaming ingest tables |
Data Governance in Each Architecture
Data governance in analytics infrastructure covers five capabilities: access control, data lineage, data quality enforcement, audit logging, and data privacy compliance. The three architectures differ significantly in how natively they support these capabilities.
| Governance Capability | Data Warehouse | Data Lakehouse |
|---|---|---|
| Column-level access control | Native in all major platforms | Unity Catalog (Databricks), Lake Formation (AWS), BigLake (GCP) |
| Row-level security | Native in Snowflake, BigQuery, Redshift |
Delta Lake row filters, Iceberg row-level access control |
| Data lineage tracking | Requires external tooling (Atlan, DataHub) |
Delta Lake lineage, Unity Catalog lineage, Apache Atlas |
| Data quality enforcement | dbt tests, Great Expectations in pipeline | Great Expectations, Soda Core, Delta Live Tables expectations |
| Audit logging | Native query audit logs in all major platforms | Cloud storage audit logs, Unity Catalog audit log |
| GDPR right to erasure | DELETE supported natively | Deletion vectors (Iceberg/Delta) enable row-level deletes on Parquet |
Unity Catalog, Databricks’ unified governance layer, applies the same access control policies across all data assets: Delta Lake tables, Iceberg tables, ML models, dashboards, and notebooks. It provides column masking, row filters, and data lineage that tracks how data flows from source tables through transformation notebooks into downstream tables and dashboards. For organizations running the full analytics and ML lifecycle on Databricks, Unity Catalog eliminates the need for separate governance tooling for each layer of the stack.
ELT Pipelines and Data Transformation Tools
The transformation layer between raw source systems and the analytics layer is where most of the engineering effort in a modern data platform lives. The shift from ETL (transform before loading) to ELT (load first, transform inside the warehouse or lake) has been driven by the decreasing cost of cloud storage and the increasing power of warehouse and lakehouse query engines for transformation workloads.
dbt: The Standard Transformation Framework
dbt (data build tool) has become the standard transformation framework for analytics engineering in both warehouse and lakehouse environments. It expresses data transformations as SQL SELECT statements organized into a directed acyclic graph (DAG) of dependencies. dbt compiles these SELECT statements into CREATE TABLE AS SELECT or CREATE VIEW statements and executes them in dependency order, ensuring that upstream models are materialized before downstream models that depend on them.
| dbt Feature | Value |
|---|---|
| SQL-based transformations | Analytics engineers work in SQL without needing Python or Spark expertise |
| Dependency graph | Automatic execution order based on model references; no manual scheduling |
| Built-in testing | Schema tests (not null, unique, accepted values) and custom SQL tests on every model |
| Documentation generation | Auto-generated data catalog with column descriptions and lineage from model definitions |
| Incremental models | Process only new or changed rows rather than full table rebuilds on each run |
| Warehouse and lakehouse support | Native adapters for Snowflake, BigQuery, Redshift, Databricks, Spark, and Trino |
Ingestion Tools: Getting Data Into the Platform
| Tool | Approach | Best Fit |
|---|---|---|
| Fivetran | Managed connectors, automatic schema migration, 500+ sources |
Teams wanting zero-maintenance source connectors with SLA guarantees |
| Airbyte | Open-source connectors, self-hosted or managed cloud, 300+ sources |
Cost-sensitive teams wanting connector flexibility with self-hosting option |
| AWS Glue | Serverless Spark ETL, built-in crawlers, Glue Data Catalog |
AWS-native pipelines with serverless execution and S3 as the target |
| Apache Kafka + Kafka Connect | Real-time streaming ingestion, 200+ connectors |
Teams needing sub-minute data freshness from operational databases |
| Debezium (CDC) | Change Data Capture from MySQL, PostgreSQL, MongoDB |
Near-real-time replication of operational database changes into the lake |
Real-Time Analytics: Closing the Batch Gap
Batch processing pipelines that refresh analytics data hourly or daily are adequate for historical reporting but inadequate for operational analytics, fraud detection, personalization, and live dashboards. The modern data platform increasingly needs to serve both batch analytics with high data completeness and real-time analytics with low latency, from the same underlying data store.
The Lambda architecture addresses this by maintaining two parallel processing paths: a batch layer that produces accurate but delayed results and a speed layer that produces approximate but immediate results. Queries merge results from both layers. The operational complexity of maintaining two separate codebases that must produce consistent results has led most organizations to prefer the Kappa architecture, which uses a single stream processing pipeline for all data, with batch semantics expressed as large streaming windows rather than separate batch jobs.
Apache Iceberg’s streaming write support, combined with Flink as the stream processing engine and Trino as the query engine, produces a streaming lakehouse architecture where data is queryable within seconds of being produced. AWS Kinesis Data Firehose writes directly to S3 in Parquet format with Iceberg metadata, making streaming data immediately accessible to Athena queries without a separate ingestion service. This architecture collapses the Lambda complexity into a single storage layer that serves both real-time and historical queries.
Architect Your Analytics Infrastructure
| Architecture Pattern | Data Freshness | Operational Complexity |
|---|---|---|
| Batch ETL to warehouse | Hours to daily | Low: simple pipelines, predictable scheduling |
| Lambda (batch + speed layers) | Seconds for speed layer | High: two codebases, result merging, consistency management |
| Kappa (streaming only) | Seconds to minutes | Moderate: single codebase, stream processing expertise required |
| Streaming lakehouse (Flink + Iceberg) | Seconds to minutes | Moderate: unified storage, modern tooling, growing ecosystem |
The Modern Data Stack in 2026
The modern data stack has converged on a set of well-defined layers, each served by a competitive ecosystem of tools. Understanding the standard stack components helps organizations avoid building custom solutions where mature tooling already exists and focus engineering effort on the layers that are genuinely specific to their business.
| Stack Layer | Leading Tools in 2026 |
|---|---|
| Ingestion (batch) | Fivetran, Airbyte, AWS Glue, Azure Data Factory |
| Ingestion (streaming) | Kafka, Debezium, Kinesis, Pub/Sub, Flink CDC |
| Storage | S3, GCS, Azure Data Lake Storage Gen2 |
| Table format | Apache Iceberg, Delta Lake, Apache Hudi |
| Transformation | dbt, Spark, Flink, SQL on warehouse engine |
| Orchestration | Apache Airflow, Dagster, Prefect, Temporal |
| Query engine | Trino, Spark SQL, Databricks SQL, BigQuery, Redshift, Athena |
| Semantic layer | dbt Semantic Layer, Looker LookML, AtScale, Cube.dev |
| BI and visualization | Tableau, Looker, Power BI, Metabase, Grafana |
| Data catalog and governance | Unity Catalog, DataHub, Atlan, OpenMetadata |
| Data quality | Great Expectations, Soda Core, Monte Carlo, Bigeye |
Decision Framework: Choosing the Right Architecture
The choice between a data warehouse, a data lake, and a data lakehouse is not a permanent architectural decision. Most organizations evolve through these architectures as their data maturity, team skills, and business requirements grow. Understanding where on that maturity curve your organization sits is as important as understanding the technical differences between the architectures.
| Organizational Context | Recommended Architecture | Rationale |
|---|---|---|
| Small team, primarily structured data, BI focus | Cloud data warehouse (Snowflake or BigQuery) | Low operational overhead, strong BI integration, fast time to value |
| Data science team needing raw data access | Data lake (S3 + Spark) or lakehouse | Raw data preservation, ML framework compatibility, schema flexibility |
| Multiple teams with mixed SQL and Python needs | Lakehouse (Databricks or Iceberg-based) | Unified platform serves analysts, engineers, and data scientists |
| Real-time analytics requirement alongside batch | Streaming lakehouse (Iceberg + Flink) | Single storage layer for both streaming and batch queries |
| Strict governance: GDPR, HIPAA, financial audit | Warehouse or lakehouse with Unity Catalog / Lake Formation | Column-level access control, lineage, and audit logging required |
| Existing heavy Snowflake investment | Expand with Snowflake Iceberg tables | Leverage existing investment while extending to open formats |
| Cost-driven, large volume, flexible workloads | Lakehouse on open formats (Iceberg + Trino) | Lowest storage cost, no vendor lock-in, compute choice flexibility |
The broader data engineering and backend architecture context for these decisions connects across the Database Architecture and Performance series published this week on the Askan Technologies blog, including the March 23 article on PostgreSQL vs MySQL vs MongoDB, the March 24 article on database scaling strategies, and the March 25 article on event-driven architecture. Organizations building analytics infrastructure on top of operational databases built with these principles benefit from the alignment between operational and analytical data models.
The full-stack software engineering and data platform capabilities at Askan Technologies cover analytics infrastructure design, ELT pipeline engineering, warehouse and lakehouse migration, and data governance framework implementation for organizations at every stage of data maturity.
Common Pitfalls in Analytics Infrastructure Projects
| Pitfall | Consequence | Prevention |
|---|---|---|
| Building a data lake without governance | Data swamp: data present but unusable without heroic effort to find and trust it | Implement medallion architecture, data catalog, and quality checks from day one |
| Over-engineering with a lakehouse before team is ready | Complexity without benefit; team spends time on infra instead of analytics | Start with managed warehouse; migrate when specific lakehouse capability is needed |
| No data quality enforcement in pipelines | Corrupt or incomplete data reaches analysts silently; dashboard numbers wrong | dbt tests and Great Expectations checks on every transformation layer |
| Ignoring small file problem in streaming ingest | Query performance degrades over time as thousands of tiny files accumulate | Schedule regular OPTIMIZE / compaction jobs on streaming tables |
| No partitioning strategy on large tables | Full scans on every query; warehouse or lake performance collapses at scale | Partition by date and frequently filtered columns at table creation, not after |
| Single analytics layer for all consumers | BI dashboards, ML training jobs, and real-time queries compete for same resources | Separate compute pools for different workload types; isolate ML from BI compute |
Architect Your Analytics Infrastructure
Most popular pages
-

Async Communication in Engineering Teams: When Fewer Meetings Produce Better Code
There is a version of the engineering day that many developers know well. The calendar is split into one-hour blocks. Stand-ups run long. Syncs...
-

Ecommerce Platform Migration: Engineering Checklist Before You Switch
Switching your ecommerce platform is one of the most consequential engineering decisions a team can make. Done well, it unlocks better performance, cleaner architecture,...
-
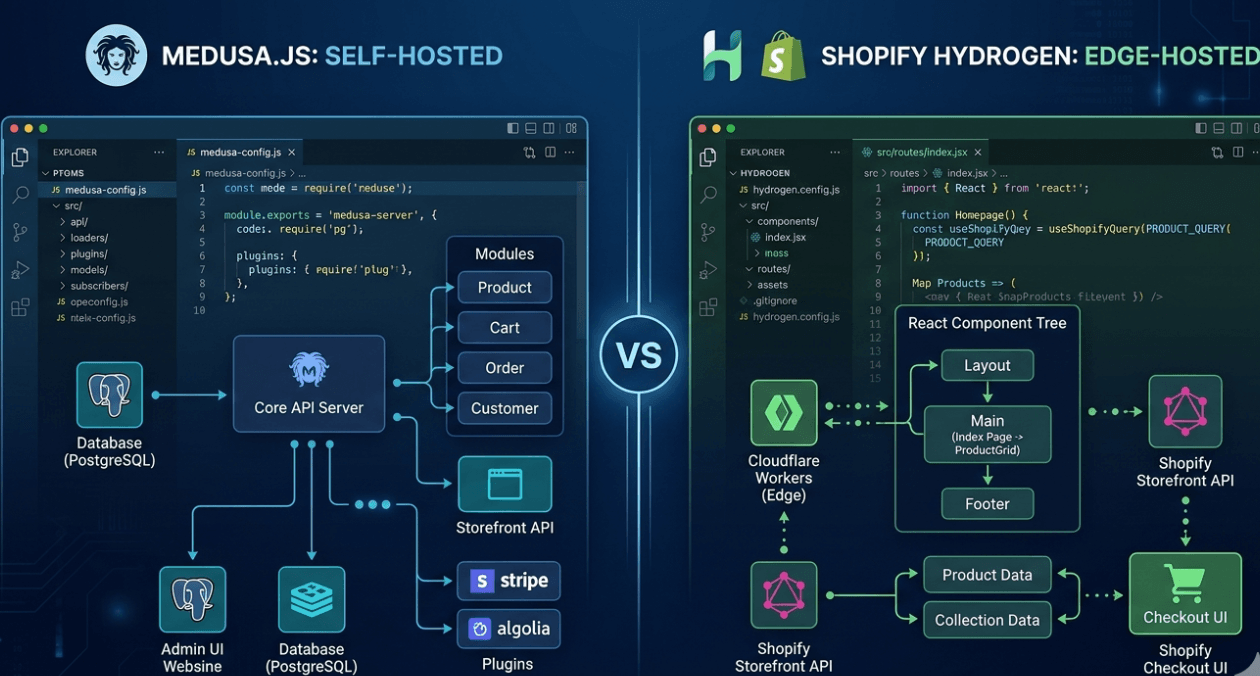
Medusa.js vs Shopify Hydrogen: Which Headless Commerce Stack Should You Build On?
The headless commerce conversation has shifted. Teams are no longer asking whether to go headless. They are asking which stack actually holds up once...
Async Communication in Engineering Teams: When Fewer Meetings Produce Better Code
There is a version of the engineering day that many developers know well. The calendar is split into one-hour blocks. Stand-ups run long. Syncs...
Ecommerce Platform Migration: Engineering Checklist Before You Switch
Switching your ecommerce platform is one of the most consequential engineering decisions a team can make. Done well, it unlocks better performance, cleaner architecture,...
Medusa.js vs Shopify Hydrogen: Which Headless Commerce Stack Should You Build On?
The headless commerce conversation has shifted. Teams are no longer asking whether to go headless. They are asking which stack actually holds up once...