



TABLE OF CONTENTS
Event-Driven Architecture: When to Use Message Queues, Event Streams, and Pub/Sub

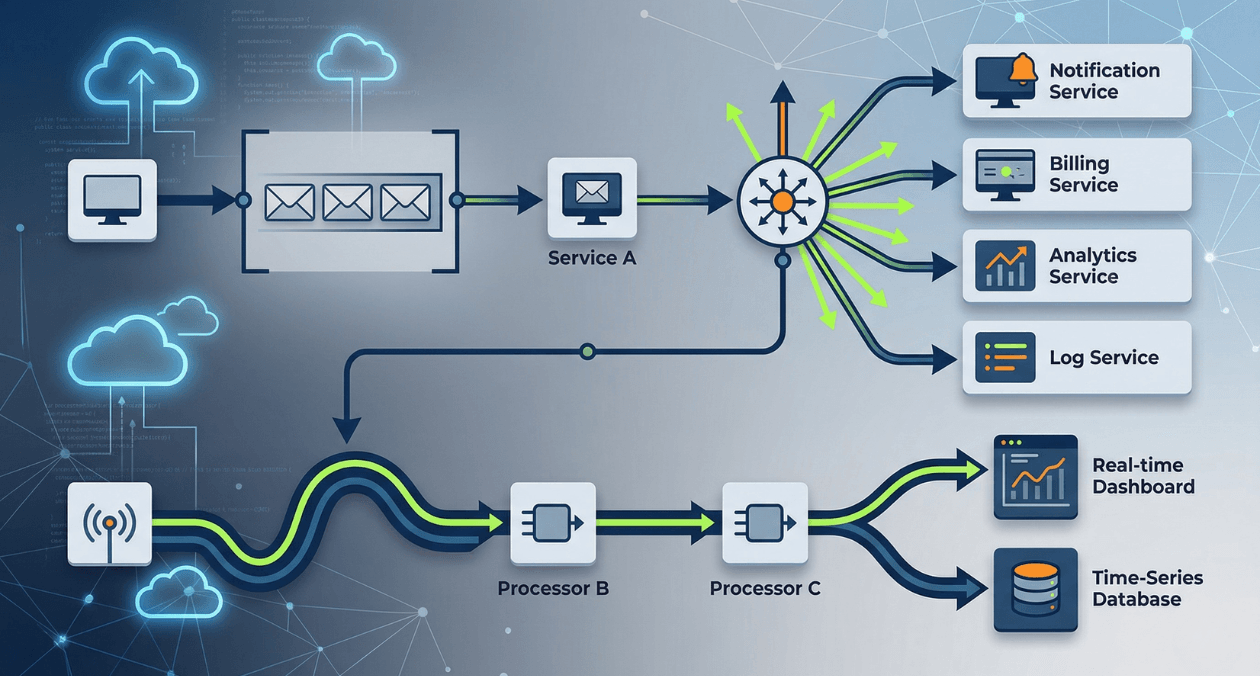
Synchronous request-response is the default communication model for most web applications. A service calls another service, waits for the response, and continues. At low traffic volumes and shallow service graphs this model works without visible friction. At scale, the friction becomes structural: a slow downstream service delays every caller. A service that is temporarily unavailable cascades failures upstream. A spike in traffic to one component overwhelms another because there is nothing between them to absorb the surge.
Event-driven architecture addresses these structural weaknesses by replacing direct synchronous calls with asynchronous message passing. Producers emit events or messages without waiting for consumers to process them. Consumers process at their own pace. Neither side needs to be available at the same moment. The communication happens through an intermediary, the messaging infrastructure, that decouples producer availability from consumer availability and absorbs traffic variance between them.
The three primary forms of asynchronous messaging, message queues, event streams, and publish/subscribe systems, are often used interchangeably in conversation but represent meaningfully different architectural patterns with different guarantees, different operational characteristics, and different use cases. Choosing the wrong one for a given problem introduces complexity without solving the underlying challenge, while choosing the right one produces systems that are more resilient, more scalable, and easier to evolve independently.
This guide provides a precise technical breakdown of each pattern, the platforms that implement them, how they compare across the dimensions that matter most in production, and the decision framework that solution architects, backend developers, and system designers rely on to match the right pattern to each problem.
The Core Problem That Asynchronous Messaging Solves
Synchronous Coupling and Its Costs
When Service A calls Service B synchronously, three dependencies are created simultaneously. A runtime dependency: Service B must be available when A calls it. A performance dependency: Service A’s response time is bounded from below by Service B’s response time. A scaling dependency: when A scales up, B must also scale to handle A’s increased call volume or become the bottleneck.
In a microservices system with ten services in a call chain, these dependencies multiply. The availability of the entire chain is the product of the individual service availabilities. Ten services each at 99.9% availability produce a chain availability of approximately 99.0%. The p99 latency of the chain is the sum of the p99 latencies of every service in it. These are not theoretical concerns; they are the patterns that explain why distributed systems are so much harder to operate reliably than monoliths under the synchronous model.
What Asynchronous Messaging Provides
Asynchronous messaging replaces runtime coupling with temporal decoupling. The producer does not wait for the consumer. Messages are durable: if the consumer is unavailable when a message is produced, the message waits in the broker until the consumer recovers. Load leveling absorbs traffic spikes: a burst of ten thousand messages per second from the producer is delivered to the consumer at a rate the consumer can sustain, rather than being dropped or rejected.
| Property | What It Means in Practice |
|---|---|
| Temporal decoupling | Producer and consumer do not need to be available simultaneously |
| Load leveling | Consumer processes at its own pace; broker absorbs the burst |
| Failure isolation | Consumer failure does not propagate to producer |
| Independent scaling | Producer and consumer scale on their own metrics |
| Replay capability | Some systems allow re-reading past messages for reprocessing or debugging |
Pattern 1: Message Queues
How Message Queues Work
A message queue is a first-in, first-out buffer between a producer and one or more consumers. A producer sends a message to the queue. A consumer receives the message, processes it, and acknowledges it. Once acknowledged, the message is removed from the queue. If the consumer fails before acknowledging, the broker redelivers the message after a visibility timeout, ensuring it is processed at least once.
The defining characteristic of a message queue is competitive consumption: when multiple consumers read from the same queue, each message is delivered to exactly one consumer. This is the work distribution model. A queue of ten thousand jobs shared across ten consumer instances distributes approximately one thousand jobs to each consumer, balancing the processing load automatically without any coordination logic in the application.
Delivery Guarantees in Message Queues
| Guarantee Level | Definition | Trade-off |
|---|---|---|
| At-most-once | Message delivered once or not at all; never redelivered | Possible message loss; lowest latency overhead |
| At-least-once | Message delivered one or more times; may be redelivered on failure | Requires idempotent consumers; most common production setting |
| Exactly-once | Message delivered precisely once, never lost, never duplicated | Highest overhead; requires transactional support in broker and consumer |
Exactly-once delivery is the most expensive guarantee and the one most frequently misunderstood. True exactly-once delivery requires coordination between the message broker and the consumer’s data store within a distributed transaction. AWS SQS FIFO queues with message deduplication and Kafka transactions with idempotent producers both approximate exactly-once semantics within their specific constraints. In practice, most production systems implement at-least-once delivery and make consumers idempotent: processing the same message twice produces the same result as processing it once.
Primary Message Queue Platforms
| Platform | Strengths | Best Fit |
|---|---|---|
| AWS SQS | Fully managed, infinite scale, FIFO queues, dead-letter queues | AWS-native applications needing zero operational overhead |
| RabbitMQ | Rich routing (exchanges, bindings), multiple protocols, mature ecosystem | Complex routing rules, on-premise or multi-cloud deployments |
| ActiveMQ | JMS compliance, enterprise integration patterns, durable topics | Java/JVM enterprise systems requiring JMS standard compliance |
| Azure Service Bus | Enterprise messaging, sessions, scheduled messages, Azure-native | Microsoft Azure workloads requiring enterprise queue features |
| Google Cloud Pub/Sub (queue mode) | Auto-scaling, exactly-once delivery option, Google Cloud native | GCP-native applications with variable ingestion rates |
Dead-Letter Queues: Handling Poison Messages
A poison message is one that causes the consumer to fail every time it attempts to process it, often due to malformed data, an unexpected schema change, or a dependency failure specific to the message content. Without a safety mechanism, a poison message loops indefinitely: the consumer fails, the broker redelivers after the visibility timeout, the consumer fails again.
A dead-letter queue (DLQ) captures messages that have exceeded a configured maximum delivery attempt count. Instead of looping indefinitely, the message is moved to the DLQ after the threshold is reached. Engineers can inspect DLQ messages to diagnose the failure, fix the consumer or the message content, and reprocess the message without losing it. DLQs are not optional in production queue-based systems; they are the safety net that prevents poison messages from blocking the entire processing pipeline.
Pattern 2: Event Streams
How Event Streams Differ from Queues
An event stream is an ordered, durable log of events. Unlike a message queue where messages are removed after consumption, an event stream retains every event for a configurable retention period. Multiple consumers can read the same stream independently, each maintaining its own offset, which is its position in the stream. Consumer A reading at offset 50,000 and Consumer B reading at offset 48,000 are both reading from the same stream without interfering with each other.
This retained log model enables capabilities that queues cannot provide. A new consumer service can join a stream and read from the beginning, processing all historical events to build its initial state. A consumer that crashed can resume from its last committed offset rather than losing the messages that arrived during its downtime. An analytics pipeline can read the same event stream as the real-time processing pipeline, deriving different outputs from the same event data without the producer needing to know about either consumer.
Apache Kafka: The Dominant Event Streaming Platform
Apache Kafka is the platform that defined the modern event streaming category. Its architecture partitions each topic into an ordered, replicated log. Producers append events to a partition. Consumers in a consumer group read from partitions, with each partition assigned to exactly one consumer in the group at any given time. Adding consumers to a group increases parallelism up to the number of partitions; a topic with 12 partitions can be consumed in parallel by up to 12 consumer instances in a single consumer group.
| Kafka Concept | Definition |
|---|---|
| Topic | Named category for a stream of related events |
| Partition | Ordered, append-only sub-log within a topic; unit of parallelism |
| Offset | Sequential position of an event within a partition; consumer tracks its own |
| Consumer group | Set of consumers sharing topic consumption; each partition assigned to one member |
| Retention | Configurable time or size-based event retention (hours to forever) |
| Replication factor | Number of broker copies of each partition for fault tolerance |
Kafka’s throughput at scale is extraordinary. A well-configured Kafka cluster routinely sustains millions of events per second per broker with sub-10ms end-to-end latency. Its sequential disk write model, where producers always append to the end of a partition log, produces I/O patterns that saturate disk throughput far more efficiently than the random-access patterns of traditional message queues.
Confluent Platform extends Apache Kafka with Schema Registry (enforces Avro/JSON/Protobuf schemas on events), Kafka Connect (pre-built connectors for 200+ data sources and sinks), and Kafka Streams (stateful stream processing library). Confluent Cloud and AWS MSK (Managed Streaming for Apache Kafka) provide managed Kafka that eliminates broker management, partition rebalancing, and ZooKeeper/KRaft configuration overhead.
Stream Processing: Stateful Computation Over Event Streams
Event streams become particularly powerful when combined with stream processing frameworks that allow stateful computation over the continuous flow of events. Rather than processing each event independently, stream processors maintain state across events and produce derived outputs: aggregations, joins between streams, windowed computations, and pattern detection.
| Framework | Model | Best Fit |
|---|---|---|
| Kafka Streams | Library-based, embedded in JVM application, exactly-once semantics | Teams wanting stream processing without a separate cluster |
| Apache Flink | Distributed cluster, sophisticated state management, event-time processing | Complex stateful streaming at large scale |
| Apache Spark Structured Streaming | Micro-batch or continuous processing, unified batch and stream API | Teams already using Spark for batch analytics |
| AWS Kinesis Data Analytics | Fully managed Flink, serverless, AWS-native | AWS environments needing managed stream processing |
| Google Cloud Dataflow | Managed Apache Beam, unified batch and streaming | GCP environments, flexible windowing and exactly-once |
Architect Your Event-Driven System with Askan Technologies
Pattern 3: Publish/Subscribe (Pub/Sub)
The Pub/Sub Model
In the publish/subscribe pattern, a publisher emits messages to a named topic without any knowledge of who will receive them. Subscribers declare interest in one or more topics and receive a copy of every message published to those topics. Unlike a message queue where each message goes to exactly one consumer, pub/sub delivers each message to all current subscribers. Unlike an event stream where consumers read at their own pace from a durable log, most pub/sub systems are push-based: messages are delivered to active subscribers immediately and are not stored for late-arriving subscribers by default.
The pub/sub pattern is the natural fit for event notification workloads where multiple independent consumers need to react to the same event. An order-placed event published to an order topic might be consumed simultaneously by an inventory service, a fulfillment service, an email notification service, and an analytics pipeline. The order service does not need to know about any of these consumers. Adding a new consumer requires only a new subscription, with no changes to the publisher.
Fan-Out Architecture with Pub/Sub
The fan-out capability of pub/sub is its defining architectural advantage. A single published event reaches an unbounded number of subscribers simultaneously. This enables the choreography pattern in microservices architecture: instead of a central orchestrator calling each downstream service in sequence, each service subscribes to the events it cares about and reacts independently. The coupling is reduced to the event schema rather than direct service-to-service dependencies.
Major Pub/Sub Platforms
| Platform | Delivery Model | Key Characteristic |
|---|---|---|
| AWS SNS | Push to SQS, Lambda, HTTP endpoints, email, SMS | Native AWS fan-out; pairs with SQS for durable delivery |
| Google Cloud Pub/Sub | Push or pull, at-least-once, optional exactly-once | Auto-scaling, global, serverless, deep GCP integration |
| Redis Pub/Sub | In-memory push, no persistence, fire-and-forget | Ultra-low latency notifications; no durability guarantee |
| MQTT (broker: Mosquitto, EMQX) | Push to active subscribers, QoS levels 0/1/2 | IoT devices with constrained resources and intermittent connectivity |
| Azure Service Bus Topics | Push to topic subscriptions with filter rules | Azure-native fan-out with server-side message filtering |
SNS + SQS: Combining Fan-Out with Durable Queuing
A common AWS architecture pairs SNS and SQS to combine the fan-out capability of pub/sub with the durability and competitive consumption of message queues. An event is published to an SNS topic, which fans it out to multiple SQS queues, one per downstream service. Each downstream service consumes from its own dedicated SQS queue at its own pace, with dead-letter queue protection and independent scaling.
This pattern solves the durability gap in pure pub/sub: if a subscriber is temporarily unavailable when an SNS message is delivered, the message is caught by the SQS queue rather than lost. The subscriber recovers and processes the queued messages in order. The SNS topic provides fan-out without coupling; the SQS queues provide durability and load leveling. Each service in the fan-out can have different retry policies, visibility timeouts, and dead-letter queue configurations.
Core Comparison: Queues vs. Streams vs. Pub/Sub
Fundamental Differences at a Glance
| Dimension | Message Queue | Event Stream |
|---|---|---|
| Message retention | Deleted after successful acknowledgment | Retained for configured duration regardless of consumption |
| Consumer model | Competitive: one consumer per message | Independent: each consumer group reads all messages |
| Ordering guarantee | FIFO within queue (standard or strict) | Strict ordering within a partition |
| Replay capability | No: messages consumed and deleted | Yes: rewind to any offset within retention window |
| Typical latency | Milliseconds (SQS standard) to sub-millisecond (RabbitMQ) | Sub-10ms at high throughput (Kafka) |
| Throughput ceiling | Millions of messages/sec with sharding | Millions of events/sec per partition natively |
| Dimension | Pub/Sub | Best Pattern For |
|---|---|---|
| Message retention | Usually none (push to active subscribers only) | Transient notifications, real-time fan-out |
| Consumer model | Broadcast: all subscribers receive every message | Multi-service event notification |
| Ordering guarantee | Generally not guaranteed across subscribers | Workloads where order per subscriber matters less than reach |
| Replay capability | Usually no (platform-dependent) | New subscriber integration challenges without stream complement |
| Typical latency | Sub-millisecond (Redis Pub/Sub) to low milliseconds | Real-time dashboards, live notifications, IoT telemetry |
| Throughput ceiling | Very high (Google Pub/Sub scales to millions/sec) | High fan-out broadcast to many subscribers |
Choosing Between the Three Patterns
| Use Case | Recommended Pattern | Reasoning |
|---|---|---|
| Background job processing (image resize, email send) | Message queue | Work distribution across consumers, each job processed once |
| Real-time analytics pipeline | Event stream (Kafka) | Multiple consumers, replay for backfill, ordered history |
| Microservice event notification (order placed) | Pub/Sub or SNS+SQS | Fan-out to many independent services without coupling |
| User activity tracking at scale | Event stream (Kafka) | High throughput, durable log, multiple downstream consumers |
| IoT device telemetry ingestion | Event stream or MQTT + stream | High write volume, multiple processing pipelines |
| Task scheduling with retry logic | Message queue with DLQ | Exactly-once processing semantics, failure handling |
| Live notifications (chat, alerts) | Pub/Sub (Redis or WebSocket) | Low latency, broadcast, no persistence requirement |
| Audit trail and event sourcing | Event stream (Kafka) | Immutable ordered log, replay for state reconstruction |
Event-Driven Architecture Patterns
Event Sourcing
Event sourcing stores application state as a sequence of immutable events rather than as mutable rows in a database. Instead of updating an order’s status column from pending to fulfilled, an event sourcing system appends an OrderFulfilled event to the order’s event log. The current state of any entity is derived by replaying all events in its log from the beginning.
The event log serves as the authoritative source of truth. It provides a complete audit trail of every state transition. It enables temporal queries: what was the state of this order at 14:32 yesterday? It supports event replay for building new read models or correcting data corruption by replaying events through a corrected processing function.
Event sourcing requires an event store, which is functionally similar to an event stream. Apache Kafka is commonly used as the underlying event store for event sourcing systems. EventStoreDB is a purpose-built database for event sourcing that provides native support for event streams per aggregate, optimistic concurrency control, and subscriptions for projecting events into read models.
CQRS: Command Query Responsibility Segregation
CQRS separates the write model from the read model of an application. Commands change state and are handled by the write side. Queries retrieve state and are served by the read side. The two sides can use different data stores optimized for their specific access patterns. The write side uses an event store for append-only writes. The read side materializes events into denormalized read models in a relational database, a document store, or a search index, whichever produces the best query performance for the specific view.
CQRS and event sourcing are complementary patterns that are often implemented together. Events produced by the write side are consumed by read-side projectors that update the read models. The read models are eventually consistent with the write side: there is a brief window where a command has been applied but the read model has not yet been updated. This eventual consistency is a trade-off that most applications can accept in exchange for the independent scaling and query optimization that the pattern provides.
| CQRS Component | Responsibility |
|---|---|
| Command handler | Validates command, applies business rules, appends events to event store |
| Event store | Durable, ordered log of domain events per aggregate |
| Event projector | Consumes events from store, updates denormalized read model |
| Read model store | Optimized for query access patterns: relational, document, or search index |
| Query handler | Reads from read model store; no business logic, fast and simple |
Saga Pattern: Distributed Transactions Without Two-Phase Commit
Distributed transactions that span multiple services are notoriously difficult to implement correctly. Two-phase commit (2PC) provides strong consistency guarantees but requires all participating services to be available simultaneously and introduces blocking locks across service boundaries, creating exactly the tight coupling that microservices are designed to avoid.
The Saga pattern replaces distributed transactions with a sequence of local transactions, each of which publishes an event that triggers the next step. If any step fails, compensating transactions are executed in reverse order to undo the completed steps. A hotel booking saga might involve local transactions in the flight service, hotel service, and payment service, each publishing events that trigger the next step. If the payment service fails, compensating events trigger the flight and hotel reservations to be released.
Architect Your Event-Driven System with Askan Technologies
Schema Management and Event Contracts
Events shared between services are inter-service contracts. A producer that changes an event schema without coordinating with consumers breaks those consumers. In a synchronous system, a breaking API change fails immediately at the HTTP boundary. In an event-driven system, a breaking schema change may not surface until a consumer processes a message with an unexpected structure, potentially hours or days after the change was deployed.
Schema Registry solves this problem by enforcing schema compatibility rules on every event produced to or consumed from a Kafka topic. Confluent Schema Registry supports three compatibility levels: backward (new schema can read old data), forward (old schema can read new data), and full (both directions). Producers must register the schema before producing events, and the registry rejects schemas that violate the configured compatibility rule.
| Schema Evolution Rule | What It Allows |
|---|---|
| Backward compatible | Add optional fields; remove fields; consumers using old schema still work |
| Forward compatible | Remove optional fields; add fields; producers using old schema still work |
| Full compatible | Intersection of backward and forward; safest but most restrictive |
| Breaking change process | New topic version (v2 topic), dual-write period, consumer migration, deprecation |
Avro, Protocol Buffers (Protobuf), and JSON Schema are the three most common event serialization formats in event-driven systems. Avro is the native format for Confluent Schema Registry and provides compact binary encoding with schema evolution support. Protobuf produces the smallest binary payloads and is the preferred format for high-throughput systems where serialization overhead is a meaningful cost. JSON Schema trades compactness for human readability and is appropriate for systems where event debuggability matters more than throughput efficiency.
Operational Concerns: Observability and Failure Handling
Distributed Tracing Across Asynchronous Boundaries
One of the most significant operational challenges in event-driven systems is maintaining trace context across asynchronous message boundaries. In a synchronous call chain, the trace ID propagates automatically through HTTP headers. When a service emits a message to a queue or stream and a different service processes it later, the trace context must be explicitly carried in the message headers and extracted by the consumer to continue the trace.
OpenTelemetry provides context propagation utilities that handle this correctly. The producer extracts the current trace context and injects it as message headers. The consumer extracts the context from message headers and creates a new span as a child of the producer’s span. The resulting trace shows the complete path from the original HTTP request through the asynchronous boundary to the consumer’s processing, enabling the same end-to-end diagnostics that synchronous systems provide natively.
The observability principles and tooling covered in the March 18 article on building observable systems apply directly to event-driven systems, with the additional requirement of cross-boundary trace context propagation through message headers.
Consumer Lag Monitoring
Consumer lag measures how far behind a Kafka consumer group is from the latest offset on each partition. A lag of zero means the consumer is processing events as fast as they arrive. A growing lag indicates that the consumer is falling behind the production rate, either because the producer is generating events faster than the consumer can process them or because the consumer has failed and stopped processing entirely.
| Lag Scenario | Response |
|---|---|
| Stable non-zero lag | Consumer processes at a rate below production; add consumer instances |
| Rapidly growing lag | Consumer failure or severe processing bottleneck; investigate immediately |
| Lag spike then recovery | Transient processing delay; likely acceptable if lag recovers within SLO |
| Lag on specific partitions only | Hot partition or consumer instance failure; check consumer assignment |
Prometheus exporters like kafka-exporter and the Confluent JMX metrics pipeline expose consumer group lag as Prometheus metrics. Alerting on consumer lag that exceeds a threshold proportional to the expected processing time per event creates an early warning system that detects consumer problems before the lag becomes large enough to affect downstream data freshness SLOs.
Idempotency: The Foundation of At-Least-Once Reliability
At-least-once delivery, the standard guarantee for most production messaging systems, means that under failure conditions a message may be delivered more than once. A consumer that fails after processing a message but before committing its offset receives the same message again on restart. A consumer that receives a duplicate must produce the same result as if it processed the message once.
Idempotent consumers use a deduplication key, typically the message ID or a business-level identifier derived from the event content, to detect and discard duplicate deliveries. The deduplication state can be maintained in a database (a processed_events table keyed on message ID), in Redis (a set of recently processed message IDs with TTL), or through idempotent write operations in the downstream data store (upsert rather than insert, conditional updates rather than unconditional writes).
Message Queue vs. Event Stream: The Migration Decision
Teams frequently start with a message queue because it is simpler to operate and sufficient for early-stage workloads. As the system grows, the need for event replay, multiple independent consumers reading the same event stream, or audit trail capabilities creates pressure to migrate toward an event streaming platform. Understanding the migration trigger points avoids premature complexity while also avoiding the more painful refactoring of migrating under operational pressure.
| Signal | Recommended Action |
|---|---|
| Need a second service to consume the same events already going to Service A | Migrate to event stream or add SNS fan-out in front of existing SQS queue |
| Need to replay events to rebuild a read model or debug a data issue | Migrate to event stream with sufficient retention |
| Single consumer, work distribution only, no replay needed | Message queue is sufficient; do not add Kafka overhead |
| High-volume telemetry with multiple downstream pipelines | Event stream from the start; queue is under-powered for this pattern |
| Simple task queue (background jobs, scheduled work) | Message queue; event stream is overengineered for this workload |
Platform Selection Guide
Selecting a messaging platform is a decision that shapes the operational skills your team needs to develop, the cloud vendor relationships you create, and the throughput ceiling your architecture can reach. The following framework maps platform characteristics to organizational and technical context.
| Context | Recommended Platform | Reason |
|---|---|---|
| AWS-native, managed simplicity, task queues | SQS (standard or FIFO) | Zero operational overhead, deep AWS service integration |
| AWS-native, fan-out to multiple services | SNS + SQS | Durable pub/sub fan-out, per-subscriber queuing |
| High-throughput event streaming, replay needed | Apache Kafka or Confluent Cloud | Industry standard, highest throughput, rich ecosystem |
| AWS-managed Kafka | Amazon MSK | Kafka without broker management |
| Complex routing rules, on-premise or hybrid | RabbitMQ | Exchange types (direct, fanout, topic, headers), mature tooling |
| GCP-native, serverless, global | Google Cloud Pub/Sub | Auto-scaling, exactly-once option, global endpoints |
| IoT with constrained devices | MQTT + Kafka bridge | MQTT for device side, Kafka for backend processing pipeline |
| Real-time in-process notifications (low latency) | Redis Pub/Sub or Redis Streams | Sub-millisecond latency, simple operations model |
The database architecture decisions covered in this series connect directly to event-driven design. Event sourcing systems depend on the event store’s durability and ordering guarantees, and the scaling strategies for those stores follow the same principles covered in the March 24 article on database scaling strategies. The custom software delivery capabilities at Askan Technologies span event-driven architecture design, Kafka and RabbitMQ implementation, and full-stack microservices development for teams building systems that need to scale beyond what synchronous coupling can support.
Architect Your Event-Driven System with Askan Technologies
Common Mistakes in Event-Driven Implementations
| Mistake | Consequence | Prevention |
|---|---|---|
| Publishing fat events (entire entity state) | Tight schema coupling; consumers depend on fields they do not use | Publish minimal events with enough context; consumers fetch details if needed |
| No dead-letter queue configured | Poison messages block pipeline indefinitely or are silently dropped | Configure DLQ on every queue with alert on DLQ depth |
| Consumers not idempotent | Duplicate deliveries cause duplicate side effects (double charges, double emails) | Deduplication key on every consumer before any state-changing operation |
| No consumer lag monitoring | Consumer falling behind discovered hours later from data freshness complaints | Prometheus consumer lag alerts with per-partition granularity |
| Event schema changed without compatibility check | Consumers crash on unexpected schema; silent data corruption | Schema Registry with backward or full compatibility enforcement |
| All events on a single partition | No parallelism; single-consumer throughput ceiling | Partition by entity ID to distribute load and preserve per-entity ordering |
Most popular pages
-
GitOps Beyond ArgoCD: Patterns That Scale for Large Engineering Organisations
ArgoCD became the default answer when someone said "GitOps" for a good few years. It solved the most common problem neatly: sync your Kubernetes...
-
From Prototype to Production: The Engineering Checklist That Actually Matters
Prototypes lie. They perform well in demos because they are not doing any of the work that production systems actually do. There is no...
-
Building a Developer Experience (DX) Platform: From Golden Paths to Self-Service Infrastructure
There is a measurement problem at the heart of platform engineering. The people who benefit most from a well-built internal developer platform are often...
GitOps Beyond ArgoCD: Patterns That Scale for Large Engineering Organisations
ArgoCD became the default answer when someone said "GitOps" for a good few years. It solved the most common problem neatly: sync your Kubernetes...
From Prototype to Production: The Engineering Checklist That Actually Matters
Prototypes lie. They perform well in demos because they are not doing any of the work that production systems actually do. There is no...
Building a Developer Experience (DX) Platform: From Golden Paths to Self-Service Infrastructure
There is a measurement problem at the heart of platform engineering. The people who benefit most from a well-built internal developer platform are often...