

TABLE OF CONTENTS
GraphQL vs REST vs gRPC: API Architecture Patterns for Microservices in 2026

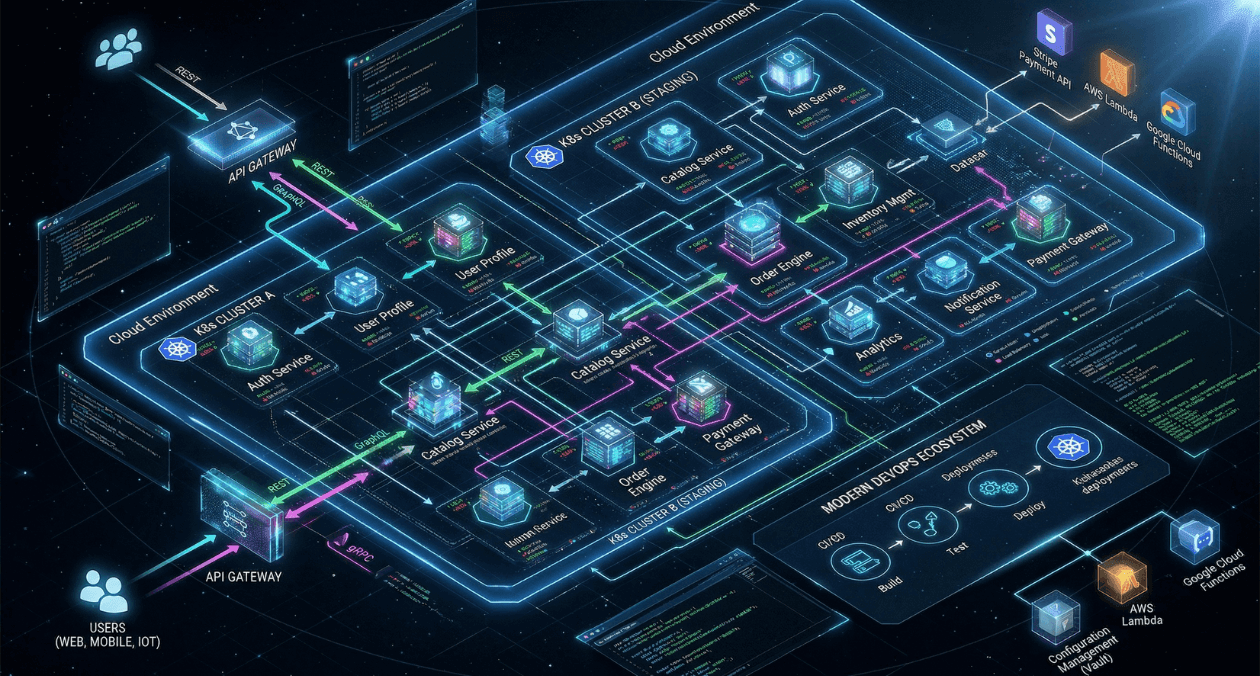
Choosing an API style is one of those decisions that compounds over time. Pick the wrong one and you end up fighting the framework every time the system grows. Pick the right one and the architecture scales cleanly as requirements change.
In 2026, most microservices teams are working with at least two of these three: REST, GraphQL, or gRPC. Each has a distinct set of trade-offs, and the right answer depends on who is consuming the API, what the data shape looks like, and how much latency tolerance exists in the system.
This guide cuts through the surface comparisons and focuses on architectural fit: where each protocol earns its place, where it creates friction, and how experienced teams are combining them inside the same system.
The Baseline: How Each Protocol Works
REST
REST structures communication around resources. Each resource has a URL, and the standard HTTP verbs (GET, POST, PUT, DELETE, PATCH) map to operations on those resources. The response format is typically JSON, the tooling is universal, and every developer on the team already understands how it works.
REST is stateless by design. Each request carries enough context for the server to respond without relying on prior interactions. This makes REST services easy to cache, easy to load balance, and easy to debug because any HTTP inspector shows exactly what was sent and received.
The downside is inflexibility in the response shape. You either get too much data (over-fetching) or you make multiple requests to assemble a complete view (under-fetching). For simple CRUD operations this is fine. For complex, nested data requirements it creates latency and overhead.
GraphQL
GraphQL inverts the control. Instead of the server defining what each endpoint returns, the client specifies exactly what fields it needs. A single query can retrieve data from multiple related resources in one round trip, and the response contains only what was requested.
This makes GraphQL particularly well-suited for teams where the frontend and backend evolve independently. A mobile client can request a lightweight version of the same data that a web dashboard requests at full depth, without requiring separate API versions.
The trade-offs are on the server side. Schema definition, resolver implementation, and query complexity management add engineering overhead. Caching is also more involved because GET requests with URL-based caching do not map cleanly to POST-based GraphQL queries.
gRPC
gRPC is a remote procedure call framework built on HTTP/2 and Protocol Buffers. Communication is defined as a contract using .proto files, and the generated client and server code handles serialization automatically. The binary serialization of Protocol Buffers is significantly more compact and faster to parse than JSON.
gRPC supports four communication patterns: unary (standard request-response), server streaming, client streaming, and bidirectional streaming. This makes it a natural fit for service-to-service communication, real-time data pipelines, and low-latency internal APIs.
The limitation is browser support. gRPC requires HTTP/2, and while gRPC-Web provides a browser-compatible layer, the tooling adds friction. gRPC is best treated as an internal protocol rather than a public-facing API.
| Attribute | REST | GraphQL | gRPC |
|---|---|---|---|
| Transport | HTTP/1.1 or HTTP/2 | HTTP/1.1 or HTTP/2 | HTTP/2 only |
| Payload format | JSON (typically) | JSON | Protocol Buffers (binary) |
| Browser support | Full | Full | Limited (via gRPC-Web) |
| Schema contract | OpenAPI (optional) | SDL (required) | .proto files (required) |
| Streaming | Limited | Subscriptions | Native, 4 patterns |
| Caching | HTTP caching (simple) | Complex, per-query | Application-level only |
Planning Your API Architecture for a Microservices System? Askan Technologies Delivers End-to-End Backend Solutions
Where Each API Style Belongs in a Microservices System
REST for External and Partner-Facing APIs
REST remains the safest choice for public APIs and partner integrations. The reasons are pragmatic: every HTTP client in every language supports it, the contract is easily documented with OpenAPI, and developers integrating from outside your organization do not need to learn a new toolchain.
For external-facing APIs where adoption and ease of integration are priorities, REST is the path of least resistance. Version it with path prefixes (/v1/, /v2/), document it with Swagger, and invest in a consistent error response format across all services.
GraphQL for Client-Driven Interfaces
GraphQL earns its value in systems where multiple client types (mobile, web, embedded dashboards) need different data shapes from the same backend. Rather than building separate REST endpoints for each client or loading clients with unnecessary data, a single GraphQL layer lets each consumer define its own query.
This pattern is particularly effective in product companies where the frontend team moves faster than the backend. A well-designed GraphQL schema becomes the stable contract between teams, and clients can iterate on their queries without requiring backend changes.
GraphQL also works well as a BFF (Backend for Frontend) layer that aggregates data from multiple downstream REST or gRPC services and exposes a unified schema to clients.
gRPC for Internal Service Communication
Inside a microservices mesh, gRPC is hard to beat on performance. The binary protocol reduces payload size, HTTP/2 multiplexing eliminates head-of-line blocking, and the code generation from .proto files enforces strict contracts between services.
For services that exchange high-frequency messages or need bidirectional streaming (think real-time telemetry, event pipelines, or live price feeds), gRPC handles the load efficiently. Teams using Kubernetes-based service meshes with Envoy or Istio get native gRPC load balancing and observability without additional instrumentation.
| Use Case | Recommended Protocol |
|---|---|
| Public or partner-facing APIs | REST |
| Multi-client product frontends | GraphQL |
| Internal service-to-service calls | gRPC |
| Real-time streaming pipelines | gRPC |
| BFF aggregation layer | GraphQL over gRPC downstream |
The Polyglot API Architecture: Using All Three Together
Most production microservices systems at scale do not pick one protocol and apply it uniformly. They use a layered architecture where each protocol is applied where it fits.
A common pattern looks like this: gRPC for service-to-service communication within the backend cluster, a GraphQL gateway that aggregates from internal gRPC services and exposes a typed schema to frontend clients, and REST endpoints for external integrations and webhook callbacks.
This layered approach lets each layer optimize for its own concerns. Internal services get the performance of gRPC without exposing binary protocols to external consumers. Frontend teams get the query flexibility of GraphQL without the latency of chatty REST calls. Partners and third-party integrations get the familiarity and documentation tooling of REST.
The Netflix, Shopify, and GitHub engineering teams have all published extensively on variations of this pattern. The common thread is intentional protocol selection per boundary rather than uniform adoption of a single style.
Planning Your API Architecture for a Microservices System? Askan Technologies Delivers End-to-End Backend Solutions
Performance Reality Check
The performance differences between these protocols are real but context-dependent.
gRPC with Protocol Buffers consistently outperforms JSON-based protocols in serialization and deserialization benchmarks. For high-throughput internal services processing thousands of requests per second, this matters. For a public API handling a few hundred requests per minute, it is irrelevant.
GraphQL has a reputation for being slow, but this is usually a resolver implementation problem rather than a protocol problem. N+1 query issues (where a GraphQL resolver fires a database query for each item in a list) are common and fixable with DataLoader-style batching. A well-optimized GraphQL server is fast. A poorly implemented one is not.
REST performance is largely determined by the data fetching logic behind the endpoints. Over-fetching large response payloads and the need for multiple round trips to assemble views are the main inefficiencies. These are solvable with thoughtful endpoint design and HTTP/2 adoption.
Developer Experience and Team Dynamics
Protocol choice affects more than runtime performance. It shapes how teams collaborate, how APIs are discovered, and how quickly new developers become productive.
- REST has the lowest learning curve. Any developer with HTTP experience can work with a REST API immediately
- GraphQL requires learning the schema definition language and query syntax, but the tooling (GraphiQL, Apollo Studio, Postman) makes exploration and testing straightforward
- gRPC requires understanding Protocol Buffers and the code generation workflow. The onboarding cost is higher, but the strict contracts reduce integration bugs significantly
For teams with mixed experience levels or frequent onboarding, REST or GraphQL reduces friction. For platform teams building foundational internal services where stability and performance matter more than discoverability, gRPC pays for its complexity.
Versioning and Evolution
How you evolve APIs over time is as important as the initial design.
REST versioning is typically done through URL paths or headers. It is explicit and easy to reason about, but managing multiple active versions requires discipline and can fragment the codebase.
GraphQL is designed for evolution. Fields can be deprecated without breaking existing queries, and new fields can be added without versioning. Schema evolution is smooth as long as breaking changes are avoided. When breaking changes are necessary, schema versioning tools like the Apollo Federation gateway handle the transition.
Protocol Buffers have built-in forward and backward compatibility rules. As long as field numbers are not reused and required fields are not added, .proto changes are safe across service versions. This makes gRPC-based services relatively easy to evolve without coordination between teams.
If you are already thinking about how gRPC and API design intersect with container orchestration, the discussion of service communication patterns in Kubernetes environments in our GitOps and continuous deployment guide provides useful background on how API contracts interact with infrastructure-level deployment decisions.
The official gRPC documentation at grpc.io remains the most reliable reference for understanding Protocol Buffer schema design and the four streaming patterns, particularly for teams new to the framework.
Making the Decision
Here is a practical way to approach the choice for a new service or a migration:
- If the API will be consumed by external developers or partners, default to REST
- If multiple frontend clients need different data shapes from the same backend, introduce GraphQL as a gateway layer
- If the service will primarily be called by other internal services and handles high request volume, evaluate gRPC
- If you are building real-time features like live feeds, event streaming, or collaborative tools, gRPC bidirectional streaming or GraphQL subscriptions are both viable depending on whether the consumers are internal or client-facing
- Do not force a single protocol across the entire system; use the right tool per boundary
The teams that build robust microservices APIs are not the ones that standardize on a single protocol. They are the ones that understand each protocol well enough to deploy it where it belongs and build the tooling to make multiple protocols work together coherently.
Planning Your API Architecture for a Microservices System? Askan Technologies Delivers End-to-End Backend Solutions
Most popular pages

Time-Series Databases: InfluxDB vs TimescaleDB vs Prometheus for IoT and Monitoring
A temperature sensor on a factory floor records a reading every five seconds. A Kubernetes cluster emits thousands of metrics per minute from every...
-
Real-Time Data Sync Across Distributed Systems: CRDT, Operational Transform, and Event Sourcing
Two users open the same document from different continents. One adds a sentence at the top. The other deletes a paragraph in the middle....
-
Data Warehouse vs Data Lake vs Data Lakehouse: Analytics Infrastructure for 2026
Every organization that generates data eventually faces a version of the same question: where should that data live so that the people and systems...
Time-Series Databases: InfluxDB vs TimescaleDB vs Prometheus for IoT and Monitoring
A temperature sensor on a factory floor records a reading every five seconds. A Kubernetes cluster emits thousands of metrics per minute from every...
Real-Time Data Sync Across Distributed Systems: CRDT, Operational Transform, and Event Sourcing
Two users open the same document from different continents. One adds a sentence at the top. The other deletes a paragraph in the middle....

Data Warehouse vs Data Lake vs Data Lakehouse: Analytics Infrastructure for 2026
Every organization that generates data eventually faces a version of the same question: where should that data live so that the people and systems...