



TABLE OF CONTENTS
Multi-Tenant SaaS Architecture: Building for Isolation, Scale, and Compliance

Every SaaS product eventually faces the same architectural inflection point. The first version was built for a handful of customers. Data lived in a shared database, the application ran as a single instance, and the team knew which customer owned which row because they could remember it. Then the customer count doubled, then tripled, and suddenly the questions that were easy to defer became urgent: what happens if one customer’s batch job saturates the database and degrades response times for everyone else? How do you demonstrate to an enterprise prospect that their data is isolated from other tenants? How do you comply with a customer’s data residency requirement that demands their records never leave a specific geographic region?
Multi-tenancy is not a single architectural pattern. It is a spectrum of design decisions that trade off cost efficiency against isolation strength, and the right position on that spectrum depends on your customer profile, your compliance obligations, and the operational maturity of your engineering team. Getting this wrong early is expensive to fix later because tenancy models are deeply embedded in database schemas, application logic, and infrastructure configuration. Getting it right from a reasonable starting point, even if that starting point is not the ideal end state, makes the subsequent migrations manageable.
This guide covers the three primary tenancy models and their honest tradeoffs, the data isolation strategies available within each model, the noisy neighbour problem and how to solve it, compliance implications including GDPR and SOC 2, and the migration path from a shared model toward greater isolation as your enterprise customer base grows.
The Three Tenancy Models and What Each Actually Costs
Before examining implementation details it is worth being precise about what the three models are and what the word cost means in each context. Cost here refers not just to infrastructure spend but to engineering complexity, operational overhead, and the risk profile each model carries.
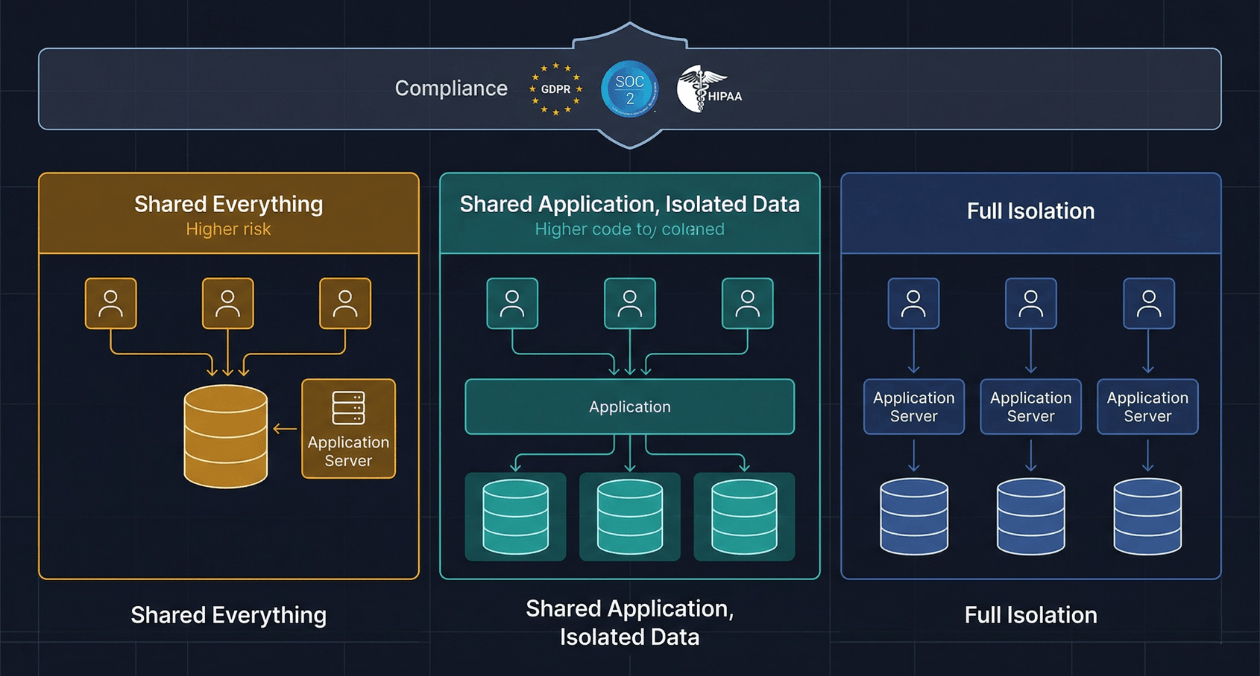
Pool Model: Shared Everything
In the pool model, all tenants share a single application deployment, a single database instance, and a single set of infrastructure resources. Tenant identity is maintained by a tenant identifier column in every table, and all queries are scoped to the current tenant’s identifier through application logic. This is the cheapest model to operate and the fastest to build initially. It is also the model that creates the most compliance exposure and the greatest risk of data leakage through application-level bugs.
The pool model is appropriate for early-stage products serving a homogeneous customer base in a single jurisdiction where customers are broadly similar in size and usage pattern. It becomes increasingly problematic as the customer base diversifies, as usage patterns diverge between large and small accounts, and as enterprise prospects begin asking security questionnaires that require you to explain your data isolation architecture.
Bridge Model: Shared Application, Isolated Data
The bridge model runs a single application deployment but gives each tenant its own isolated data store. In the database-per-tenant variant, each tenant has a separate database or schema, and the application routes queries to the correct database based on the resolved tenant identity for the current request. In the shard-per-tenant variant within a shared database server, row-level security at the database layer enforces isolation rather than relying solely on application-level scoping.
The bridge model is the most commonly adopted architecture for SaaS products serving enterprise customers because it provides meaningful data isolation at a manageable infrastructure cost. The application tier remains shared and therefore cheap to operate, while the data tier provides the isolation boundary that satisfies most enterprise security requirements and simplifies compliance scoping.
Silo Model: Full Stack Isolation
In the silo model, each tenant receives a dedicated deployment of the application, its own database, and its own compute resources. This is the most expensive model to operate because the fixed costs of the application stack are multiplied by the tenant count, but it provides the strongest isolation guarantees and the simplest compliance story. A security incident affecting one tenant’s environment cannot affect another tenant’s environment because the environments do not share any infrastructure.
The silo model is appropriate for high-value enterprise contracts where the customer’s procurement requirements mandate dedicated infrastructure, for regulated industries where shared infrastructure cannot satisfy audit requirements, and for customers with strict data residency requirements that mandate infrastructure in a specific cloud region or availability zone that no other customer uses.
| Dimension | Pool Model | Bridge Model | Silo Model |
|---|---|---|---|
| Infrastructure cost per tenant | Very low | Low to moderate | High |
| Data isolation strength | Application-level only | Database-level | Full stack |
| Compliance complexity | High (shared scope) | Moderate | Low (clean scope) |
| Noisy neighbour risk | High | Moderate (compute shared) | None |
| Deployment complexity | Low (one deployment) | Moderate | High (N deployments) |
| Enterprise sales suitability | Limited | Good for most | Ideal for regulated industries |
| Migration difficulty if model changes | High | Moderate | Low (already isolated) |
Tenant Resolution: The First Problem Every Request Must Solve
Regardless of which tenancy model you adopt, every inbound request must be resolved to a specific tenant before any application logic executes. The tenant resolution mechanism determines which database to connect to in the bridge model, which row-level security policy to activate in the pool model, or which environment to route the request to in the silo model. Getting this mechanism wrong produces the class of vulnerability known as cross-tenant data leakage, where one tenant’s request is incorrectly resolved as belonging to another tenant and returns or modifies the wrong data.
Three resolution strategies are commonly used, and they are not mutually exclusive.
| Resolution Strategy | How It Works and Where It Is Appropriate |
|---|---|
| Subdomain-based resolution | Each tenant accesses the product at a unique subdomain (tenant.yourapp.com). The subdomain is extracted from the Host header at the edge and resolved to a tenant identifier before the request hits application code. Simple to implement, easy to audit, and works well for most B2B SaaS products. |
| JWT claim-based resolution | The authenticated user’s JWT contains a tenant_id claim that was embedded at login time. Application middleware extracts this claim from the verified token on every request. More flexible than subdomain resolution for products where a user may belong to multiple tenants. |
| Custom domain resolution | Enterprise customers use their own domain (app.theircorp.com) mapped to your platform. A lookup table maps the custom domain to the internal tenant identifier. More complex to manage but required for white-label SaaS products. |
The critical security requirement in any resolution strategy is that the resolved tenant identifier must come from a source that the application controls and verifies, never from a value that the end user can supply directly in the request body or query string. A request that says ‘give me the data for tenant_id=42’ where 42 is a user-supplied parameter is an insecure direct object reference vulnerability waiting to become a data breach.
Scaling a SaaS product and hitting multi-tenancy challenges?
Database Isolation Strategies in Depth
The data layer is where the tenancy model has its most direct security implications, and the strategy you choose determines what a database-level security failure looks like and how hard it is to contain.
Row-Level Security in PostgreSQL
PostgreSQL’s row-level security (RLS) feature allows you to define policies at the table level that restrict which rows a database session can read or write based on the session’s current settings. In a multi-tenant context, you set a tenant_id session variable on every connection before any query executes, and a policy on each table restricts access to rows where the tenant_id column matches the session variable.
RLS provides a defence-in-depth layer that enforces isolation at the database level even if application-level tenant scoping has a bug. A query that forgets to include a WHERE tenant_id = :tenant clause returns no rows instead of all rows, which is a much better failure mode. The tradeoff is that connection pooling becomes more complex because session variables mean that connections cannot be freely shared between tenants without resetting the session state between requests. PgBouncer in transaction mode does not preserve session variables across borrowed connections, so teams using RLS with a connection pooler need to set the session variable at the start of every transaction.
Schema-Per-Tenant
In a schema-per-tenant design within a single PostgreSQL instance, each tenant’s tables live in a separate schema. The application sets the search_path for each database connection to the tenant’s schema before executing queries. This provides stronger isolation than row-level security because a query that omits the schema qualifier will fail rather than scanning the wrong tenant’s rows, and it makes per-tenant operations like backups and migrations easier to scope.
The practical limit of the schema-per-tenant approach is the number of schemas a single database instance can support efficiently. PostgreSQL handles hundreds of schemas without difficulty, but thousands of schemas on a single instance begins to strain catalogue operations and migration tooling. If your customer count is expected to grow into the thousands, planning a migration toward database-per-tenant or a sharding strategy before you hit this ceiling is worthwhile.
Database-Per-Tenant
Database-per-tenant provides the strongest isolation within a shared database server. Each tenant’s data is physically separated into an independent database, and the application maintains a connection pool per tenant routed through a connection multiplexer. The operational overhead is higher because migrations must be applied to each tenant database independently, monitoring must aggregate across N databases, and connection pool management becomes significantly more complex.
Tools like Flyway and Liquibase support multi-database migration execution, and frameworks like the Ruby on Rails apartment gem and the Node.js pg-multi-tenant library provide application-level abstractions that simplify tenant routing. The migration coordination challenge is real but solvable. The isolation benefit, which allows you to take a backup of a single tenant’s database independently and to give a customer verifiable evidence that their data is in a specific storage location, is worth the operational investment at the enterprise tier.
The Noisy Neighbour Problem and How to Solve It
The noisy neighbour problem arises in any shared-resource tenancy model when one tenant’s workload consumes a disproportionate share of a shared resource, degrading the experience for all other tenants. A customer running a bulk data export at peak hours, a background job that generates thousands of email notifications in a tight loop, or a tenant whose usage grows 10x in a week because of a successful product launch are all sources of noisy neighbour behaviour.
Three categories of resource require explicit throttling in a multi-tenant system.
Compute and Request Rate Limiting
API rate limiting enforces a maximum request rate per tenant at the edge before requests reach application servers. A tenant that exceeds their rate limit receives a 429 response rather than consuming server capacity at the expense of other tenants. Rate limits should be configurable per tenant plan tier, with enterprise customers receiving higher limits than free tier or trial accounts.
At the application tier, CPU-intensive background jobs should run in tenant-scoped queues with a maximum concurrency per tenant. A job queue that allows any tenant to enqueue an unlimited number of high-CPU tasks will allow a single tenant to saturate worker capacity during a bulk operation. Setting a maximum concurrent job count per tenant in the queue configuration prevents this without requiring any per-request throttling at the API level.
Database Resource Governance
In a pool or bridge model where multiple tenants share a database server, one tenant’s expensive queries can consume I/O and CPU that degrades query latency for all other tenants. PostgreSQL’s pg_query_settings extension and statement timeout settings provide some protection, but the more robust solution is to implement query-level observability that alerts on per-tenant query volume and latency, combined with a per-tenant connection limit that prevents a single tenant from holding all available connections during a long-running transaction.
For products using a bridge model with schema-per-tenant or database-per-tenant, the noisy neighbour problem at the database tier is substantially reduced because tenant databases are at least partially isolated from each other in their resource consumption. The shared resource that remains is the underlying storage I/O of the database server, which requires storage-tier monitoring to catch tenants with unusually high write amplification.
Storage Quotas
File uploads, generated reports, and cached data that are stored per tenant without size limits allow individual tenants to consume arbitrary amounts of storage. Enforcing storage quotas per tenant plan tier, tracked against a counter that is updated transactionally with each write operation, prevents unbounded storage growth from a single tenant and gives your pricing model a natural upsell lever.
Scaling a SaaS product and hitting multi-tenancy challenges?
Compliance in a Multi-Tenant Architecture
Compliance requirements do not map cleanly to tenancy models, but the tenancy model significantly affects how much work is required to achieve and maintain compliance. Understanding this relationship before you commit to a model saves substantial remediation work during the first enterprise sales process that asks for a SOC 2 report or a GDPR data processing agreement.
GDPR and Data Residency
GDPR does not require tenant data isolation in the technical sense, but it does require that you can identify, extract, and delete all personal data belonging to a specific data subject on request. In a pool model with a shared database and row-level tenancy, implementing a subject access request (SAR) and right-to-erasure workflow requires querying every table that might contain personal data for rows linked to the data subject’s identifier. This is achievable but requires a comprehensive data map and disciplined query implementation.
Data residency requirements, which are increasingly common in public sector and financial services contracts in Europe, require that specific tenants’ data is stored and processed only within a defined geographic boundary. In a pool model where all tenants share a single database in a single region, satisfying a data residency requirement for one tenant requires either moving the entire database to the required region (which breaks other tenants’ requirements) or migrating that tenant out of the pool model into a dedicated deployment in the required region. Planning for this migration from the beginning is significantly cheaper than executing it as a surprise requirement during an enterprise deal closure.
SOC 2 and Audit Scope
SOC 2 Type II certification requires demonstrating that your security controls operate effectively over a continuous period, typically six to twelve months. In a pool model, the audit scope covers all customers because the control environment is shared. In a silo model, a customer can potentially be given their own dedicated environment with its own control boundary, which can simplify the audit scope for both your certification and theirs.
The tenancy model also affects how you demonstrate logical access controls during a SOC 2 audit. An auditor reviewing a pool model wants evidence that application-level tenant scoping prevents cross-tenant data access. Evidence here typically means showing your query middleware code, your test coverage for tenant isolation, and the output of penetration testing that specifically targeted cross-tenant access. A bridge model with database-level isolation provides stronger and simpler evidence: a database user for tenant A’s schema literally cannot query tenant B’s schema because the permissions do not exist.
HIPAA and Healthcare Tenants
HIPAA-covered entities and their business associates operate under specific technical safeguards requirements around audit controls, access controls, and transmission security. If your SaaS product handles protected health information for any tenant, the entire platform is in scope for HIPAA regardless of whether only some tenants are healthcare customers. The pool model is particularly problematic here because demonstrating that PHI belonging to one tenant cannot be accessed by another tenant through application code is significantly harder than demonstrating the same through database-level access controls. Dedicated infrastructure per healthcare tenant, either through the bridge model with strict per-tenant database credentials or the silo model, is the architecture that generates the cleanest HIPAA audit evidence.
Tenant Onboarding: Automating the Provisioning Pipeline
The operational maturity of a multi-tenant SaaS product is most visible at tenant onboarding time. In a pool model, onboarding a new tenant may be as simple as inserting a row into a tenants table and returning the generated tenant identifier. In a bridge or silo model, onboarding requires provisioning a database schema or an entire stack, which needs to be automated before your customer count makes manual provisioning untenable.
The onboarding pipeline for a bridge model with schema-per-tenant typically involves the following sequence.
- The signup or sales handoff creates a tenant record in the control plane database with a unique slug that will be used for subdomain routing and internal identification.
- A background job provisions the tenant’s schema in the application database, runs the full set of database migrations against the new schema, and seeds any required reference data.
- The DNS record for the tenant’s subdomain is created programmatically via the cloud provider’s API if subdomain routing is used.
- The tenant’s initial administrator user is created and a welcome email with a magic link is dispatched.
- The control plane marks the tenant as active and the subdomain becomes live.
This entire sequence should complete in under 60 seconds for a schema-per-tenant model and under 5 minutes for a database-per-tenant model with connection pool warm-up. For silo deployments, provisioning time is measured in minutes to tens of minutes depending on the infrastructure footprint, and communicating realistic expectations to the customer during their signup experience matters.
Migrating Between Tenancy Models
The most common migration scenario is moving from a pool model toward a bridge model as enterprise customer requirements evolve. This migration is non-trivial but follows a predictable pattern when approached in stages rather than as a single cutover event.
The first stage is adding the structural changes to the pool model that make the eventual migration mechanical. This means ensuring every table has a tenant_id column, that all queries already include tenant scoping, and that the application’s tenant resolution layer is a well-defined middleware component rather than ad hoc logic scattered across controllers. A pool model with clean tenant scoping and a well-defined resolution layer is halfway to a bridge model already.
The second stage is migrating tenants incrementally. Rather than migrating all tenants simultaneously, you migrate one tenant at a time by extracting their rows into a dedicated schema, updating the routing configuration to point to the new schema, and verifying that the migrated tenant’s experience is identical. After a successful soak period, the next tenant is migrated. This approach keeps production risk low and allows the team to refine the migration tooling between each run.
The third stage is cleaning up the shared tables in the pool model as tenants are migrated out. This is where a disciplined data map and comprehensive integration test coverage pay off. Askan’s software architecture and engineering services include tenancy migration planning as a specific engagement type, covering schema design review, migration tooling implementation, and the rollback strategy that every production migration requires.
Feature Flags and Configuration Per Tenant
Multi-tenant SaaS products almost always develop a need for per-tenant configuration: feature flags that enable a capability only for tenants on a specific plan tier, configuration values that vary between tenants because of their integration requirements, and experiment flags that test a feature with a specific subset of tenants before general availability.
The simplest implementation is a tenant_configurations table in the control plane database with columns for the configuration key, the value, and the tenant_id. The application loads the relevant configuration values at request time and caches them per tenant with a short TTL. This approach works at moderate scale but becomes a hot path problem if configuration is loaded on every request without caching.
As the product matures, a dedicated feature flag system that understands tenant attributes as targeting dimensions becomes the cleaner solution. A flag that is enabled for all tenants on the Enterprise plan, or for all tenants in a specific geographic region, or for a specific named list of beta tenants, is expressed naturally in a flag management system’s targeting rules rather than as a complex query against a configuration table. The flag evaluation result is cached per tenant context and updated in real time when the flag configuration changes, which eliminates the configuration loading overhead at the request level.
Observability in a Multi-Tenant System
Standard observability tooling is not tenant-aware out of the box. A latency alert that fires when p99 response time exceeds 2 seconds tells you that something is wrong but does not tell you whether the degradation is affecting all tenants or only one. Adding tenant context to every trace, metric, and log line is the foundational practice that makes multi-tenant observability useful.
In practice this means propagating the resolved tenant identifier as a structured field in every log entry, as a trace attribute in every span, and as a label or tag on the metrics your application emits. With tenant context attached to every signal, you can filter your dashboards and alert queries by tenant, which transforms debugging from a global investigation into a tenant-scoped one.
| Observability Signal | Tenant Context to Add |
|---|---|
| Application logs | tenant_id field on every log entry; use a logging middleware that injects this from the resolved tenant context |
| Distributed traces | tenant_id span attribute on the root span of every request; child spans inherit through the trace context |
| Application metrics | tenant_id label on all custom metrics; filter dashboards and SLO alerts by tenant to detect per-tenant degradation |
| Database query logs | Include tenant schema or tenant_id in slow query log analysis to identify which tenant’s workload is generating expensive queries |
Per-tenant SLO tracking is the mature form of this practice. Rather than a single availability SLO for the product, you track availability per tenant tier, which allows you to verify that enterprise tenants on your highest support tier are receiving the service quality their contracts guarantee, and to detect when a noisy neighbour is degrading a specific tenant’s SLO before that tenant files a support ticket.
Scaling a SaaS product and hitting multi-tenancy challenges?
Most popular pages
-

AMP for Ecommerce in 2026: Is It Still Worth Implementing?
For a few years, AMP was the fastest route to a spot in Google's mobile carousel, and ecommerce teams built entire template libraries around...
-

Schema Markup for Ecommerce SEO: What Actually Moves Rankings in 2026
Most ecommerce teams treat schema markup as a checkbox for developers to tick off once and forget. That approach made sense in 2019. It...
-
Magento to Medusa.js: A Realistic Migration Roadmap for Enterprise Merchants
Enterprise merchants running large Magento catalogs are asking a harder question in 2026 than they did a few years ago. It is no longer...
AMP for Ecommerce in 2026: Is It Still Worth Implementing?
For a few years, AMP was the fastest route to a spot in Google's mobile carousel, and ecommerce teams built entire template libraries around...
Schema Markup for Ecommerce SEO: What Actually Moves Rankings in 2026
Most ecommerce teams treat schema markup as a checkbox for developers to tick off once and forget. That approach made sense in 2019. It...
Magento to Medusa.js: A Realistic Migration Roadmap for Enterprise Merchants
Enterprise merchants running large Magento catalogs are asking a harder question in 2026 than they did a few years ago. It is no longer...