

TABLE OF CONTENTS
Service Mesh Architecture: When Istio and Linkerd Are Worth the Complexity

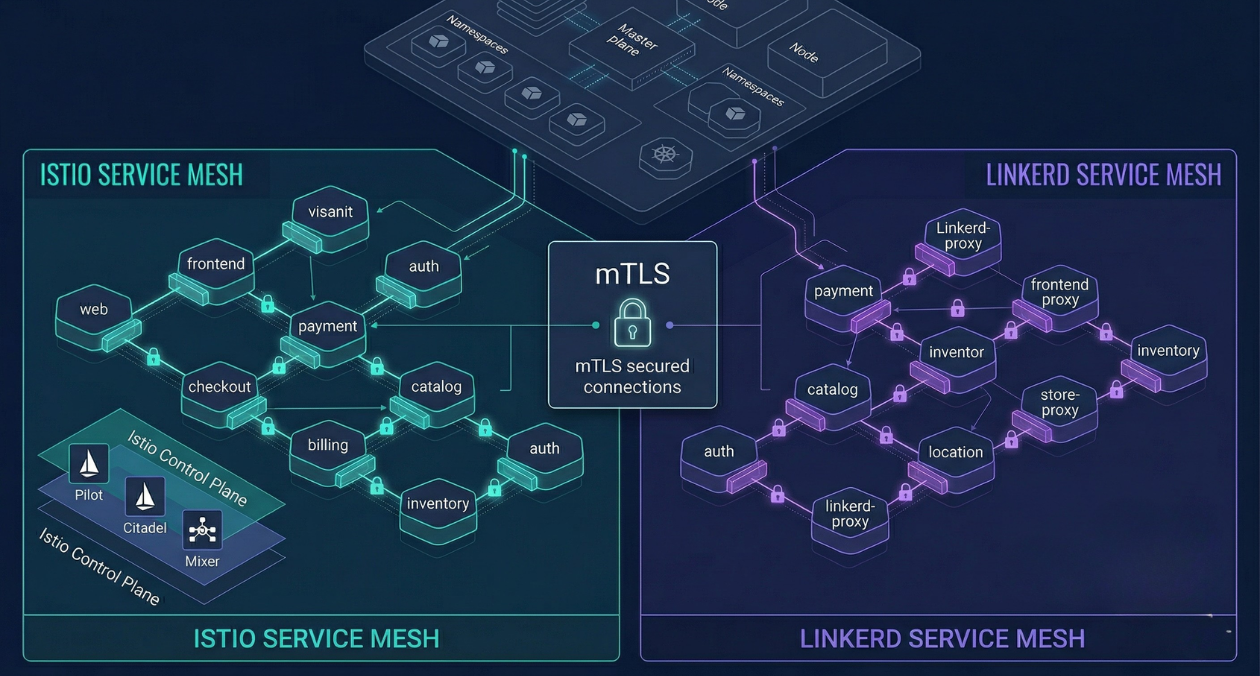
There is a specific moment in the growth of a microservices platform when the operational questions start arriving faster than the answers. How do you know which service is responsible for the latency spike you saw at 2 am? How do you enforce that service A never talks directly to service B without going through the authentication layer? How do you roll out mutual TLS across 40 services without modifying a single line of application code? These are not hypothetical problems. They are the exact friction points that every platform team encounters as a distributed system matures past a handful of services.
A service mesh is the infrastructure layer built to answer these questions. It intercepts all service-to-service traffic, applies policy, collects telemetry, and manages security at the network level without requiring application developers to change how they write code. Istio and Linkerd are the two implementations that have proven themselves in production at scale. Both solve the same class of problems and both carry real complexity costs. Understanding what that complexity buys you, and at what service count it becomes worth paying, is the decision this article is designed to help you make.
What a Service Mesh Actually Does
The core mechanism of a service mesh is the sidecar proxy. Every service pod in your cluster gets a lightweight proxy container injected alongside the application container automatically, without any change to the application image or configuration. All inbound and outbound network traffic for that pod is intercepted by the sidecar before it reaches the application or before it leaves the pod.
This interception gives the mesh four capabilities that would otherwise require each application team to implement independently.
| Capability | What It Delivers Without Application Code Changes |
|---|---|
| Traffic management | Retries, timeouts, circuit breaking, traffic splitting, canary routing at the proxy level |
| Observability | Distributed traces, per-route latency metrics, and request volume data across every service pair |
| Security | Mutual TLS between every service pair, certificate rotation, and policy-based access control |
| Resilience | Automatic retries on transient failures, load balancing strategies, and outlier detection |
The control plane is the second half of the architecture. It manages the configuration of every sidecar proxy across the cluster, distributes certificates, and exposes the API that operators use to define routing rules and access policies. The data plane is the collection of sidecar proxies themselves, which actually process traffic. This separation means the control plane can be updated or reconfigured without restarting application pods.
Istio: The Full-Featured Option and What That Means in Practice
Istio is the most feature-rich service mesh available and also the one with the steepest operational learning curve. It uses Envoy as its sidecar proxy, a high-performance C++ proxy that also powers the data planes of AWS App Mesh, Google Cloud Traffic Director, and several other managed offerings. The Envoy sidecar is capable, but its configuration API is complex, and Istio adds its own abstraction layer on top through custom resources like VirtualService, DestinationRule, Gateway, and PeerAuthentication.
The control plane has simplified significantly since the 1.5 release, which collapsed Pilot, Citadel, Galley, and Mixer into a single istiod binary. Earlier versions required running four separate control plane components, each with its own resource requirements and failure modes. The current single-binary architecture is meaningfully more approachable, but the total control plane resource footprint is still substantial compared to Linkerd.
What Istio Does Well
Traffic management is where Istio’s depth becomes genuinely useful. The VirtualService resource lets you define routing rules based on HTTP headers, URI prefixes, source labels, or weighted traffic splits, with a precision that covers nearly every progressive delivery scenario without needing an external traffic management tool. Combined with DestinationRule, which configures the load balancing algorithm, connection pool settings, and outlier detection for a specific service, you have enough control to tune traffic behaviour at a level that most teams never need to touch but are extremely glad exists when they do.
The authorization policy model is also more expressive than Linkerd’s. You can write policies that allow traffic only from specific service accounts, only on specific HTTP methods, only when a JWT claim contains a specific value. This granularity is relevant for multi-tenant platforms where the security boundaries between workloads need to be enforced at the infrastructure level rather than relying on application logic.
Where Istio Adds Real Cost
The resource overhead is measurable. Each Envoy sidecar consumes roughly 50 to 100 MB of memory at idle, and the istiod control plane itself requires several hundred MB depending on cluster size. For a cluster with 200 pods, the memory overhead of the mesh is not trivial. CPU overhead per request is also real, typically adding 1 to 3 milliseconds of latency per hop due to proxy processing.
The debugging experience when something goes wrong is another cost. Istio introduces a new failure domain that sits between your application and the network. A misconfigured VirtualService that accidentally routes 100% of traffic to a canary version, or a PeerAuthentication policy that enables strict mTLS before all pods have sidecars, will cause outages that look like application failures until you learn to look in the right place. The istioctl command-line tool and the proxy-config and analyze subcommands exist specifically to help diagnose these problems, but the learning investment is real.
Evaluating service mesh options for your platform?
Linkerd: The Lightweight Alternative with a Different Set of Tradeoffs
Linkerd takes a deliberately narrower scope than Istio. It uses a purpose-built Rust proxy called the linkerd2-proxy rather than Envoy. The proxy is smaller, consumes less memory (roughly 10 to 20 MB per sidecar at idle), and has a significantly simpler internal configuration model. There is no CRD equivalent to Istio’s VirtualService or DestinationRule. Traffic management in Linkerd is primarily handled through its integration with the Kubernetes Gateway API and through the HTTPRoute and ServiceProfile resources.
The installation experience is faster. The linkerd CLI runs pre-checks against your cluster, validates that the environment is compatible, and installs the control plane in a few minutes. The Linkerd Viz extension adds a real-time dashboard that shows success rate, request rate, and latency for every service and every route, which is genuinely useful during incidents. The dashboard is not as configurable as a Grafana setup driven by Istio’s Prometheus metrics, but it requires zero additional configuration to be useful out of the box.
Linkerd’s Real Strengths
The performance profile is the clearest advantage. Linkerd’s proxy adds sub-millisecond latency overhead per hop in typical deployments. For latency-sensitive services where every millisecond matters, this is not a minor point. The memory savings at scale also compound significantly. A cluster with 500 pods saves several gigabytes of memory by using Linkerd’s proxy instead of Envoy, which translates directly into node cost.
The operational simplicity is also a genuine advantage for smaller platform teams. The Linkerd control plane has fewer moving parts, the configuration model uses fewer custom resources, and the debugging surface is narrower. When something goes wrong with Linkerd, there are fewer places to look. For a platform team of two or three engineers managing a cluster of moderate complexity, this cognitive overhead difference matters more than the feature gap.
Where Linkerd Falls Short
Advanced traffic management scenarios that Istio handles natively require workarounds in Linkerd. Header-based routing with complex match conditions, multi-cluster traffic federation, and WebAssembly-based proxy extensions are either not supported or require additional tooling. Teams that need these capabilities will hit the ceiling of what Linkerd’s current feature set provides and will either need to layer additional tools on top or migrate to Istio.
Istio vs Linkerd: Side-by-Side Across the Dimensions That Matter
| Dimension | Istio | Linkerd |
|---|---|---|
| Proxy | Envoy (C++), general purpose | linkerd2-proxy (Rust), purpose built |
| Sidecar memory at idle | 50 to 100 MB per pod | 10 to 20 MB per pod |
| Latency overhead per hop | 1 to 3 ms typical | Under 1 ms typical |
| Traffic management depth | Very high (VirtualService, DestinationRule) | Moderate (HTTPRoute, ServiceProfile) |
| Authorization policy | Rich (method, header, JWT claims) | Service-account-level mTLS |
| Installation complexity | Moderate (Helm or istioctl) | Low (linkerd CLI) |
| Built-in observability UI | Kiali (separate install) | Linkerd Viz (included) |
| Multi-cluster support | Native (east-west gateway) | Supported via Linkerd multicluster |
| WASM extensions | Yes (EnvoyFilter) | No |
| CNCF status | Graduated | Graduated |
The Cases Where a Service Mesh Is Not the Right Answer
Adding a service mesh to every Kubernetes cluster is not a default-on decision. There are legitimate scenarios where the complexity cost outweighs the benefits, and being clear about those prevents over-engineering.
If your platform runs fewer than ten services and those services communicate through well-defined synchronous APIs or a message queue, the observability problem that a mesh solves is usually addressable through application-level instrumentation. OpenTelemetry SDKs in each service, a shared tracing backend, and structured logging give you sufficient visibility without the operational overhead of managing a mesh.
If your services are not using Kubernetes at all, neither Istio nor Linkerd applies in their standard form. Both are built around the sidecar injection mechanism that Kubernetes makes possible through mutating admission webhooks. Alternative approaches like Consul Connect exist for non-Kubernetes environments, but the operational model is different.
If your team is still establishing its Kubernetes fundamentals and does not have a dedicated platform engineering function, introducing a service mesh before those foundations are solid adds failure modes that are genuinely difficult to debug without the prerequisite knowledge. The payoff comes later; the pain arrives immediately.
| Scenario | Recommended Approach |
|---|---|
| Less than 10 services, simple communication patterns | Application-level instrumentation with OpenTelemetry, no mesh |
| 10 to 30 services, growing observability and security requirements | Linkerd for low overhead, faster adoption |
| 30 or more services, complex traffic management or strict mTLS enforcement | Istio for full feature coverage |
| Multi-cluster, multi-tenant platform with regulatory compliance needs | Istio with external CA integration |
Ambient Mesh: Istio’s Answer to the Sidecar Tax
Istio’s ambient mode is the most significant architectural shift in the service mesh space in several years. Rather than injecting a sidecar into every pod, ambient mesh moves the proxy function to a per-node layer (the ztunnel, handling L4 mTLS) and an optional per-namespace waypoint proxy (handling L7 policy and traffic management for namespaces that need it). The result is that basic mTLS and observability come with near-zero pod-level overhead, and the richer L7 capabilities are opt-in at the namespace level.
Ambient mode reached stable status in Istio 1.24 and is production-ready for teams willing to accept that it is a newer operational model than the sidecar mode. The Istio ambient mode documentation covers the architecture, supported features, and migration path from sidecar mode in detail. For greenfield platforms starting a service mesh evaluation today, ambient mode deserves serious consideration because it substantially reduces the memory overhead that has been the primary argument against Istio for smaller clusters.
Evaluating service mesh options for your platform?
Adopting a Service Mesh Without Breaking Production
The highest-risk moment in a service mesh adoption is enabling mTLS in strict mode across services that were not previously using it. If any workload still sends plaintext traffic to a service that now requires mTLS, requests fail immediately. The safe adoption path is permissive mode first.
- Install the mesh control plane and enable sidecar injection on a non-production namespace.
- Verify that sidecars are injected, that traffic flows correctly, and that the observability data appearing in the dashboard or Prometheus makes sense.
- Enable mTLS in permissive mode across namespaces. This means the proxy accepts both plaintext and mTLS traffic, so existing clients that do not have sidecars yet continue to work.
- Gradually roll sidecar injection out to all namespaces, verifying that each namespace’s services appear healthy in the mesh telemetry before moving to the next.
- Once all services have sidecars and all traffic is flowing through the mesh in permissive mode, switch to strict mTLS mode. At this point, any plaintext traffic will be rejected, which is intentional.
- Begin using traffic management features such as retries and circuit breakers incrementally, one service at a time, with monitoring in place for each change.
This sequence typically takes several weeks for a large cluster. Attempting to compress it into a single weekend migration creates the conditions for a production incident that is difficult to diagnose and blame-assign cleanly.
Observability Gains You Get Immediately After Installation
One of the most persuasive arguments for introducing a service mesh to a skeptical engineering leadership team is the observability payoff that arrives with zero application changes. Within minutes of enabling sidecar injection on a namespace, you have access to the following data that did not exist before.
- Request volume per second for every service-to-service call in the namespace, broken down by source and destination
- Success rate per route, which immediately surfaces which service pairs have elevated error rates without requiring log aggregation
- P50, P95, and P99 latency for every route, which makes it possible to answer questions like which downstream service is responsible for the latency your users are reporting
- A topology graph of which services are calling which other services, which frequently reveals undocumented dependencies that only become apparent when you visualize the actual traffic
This observability layer is complementary to application-level tracing, not a replacement for it. The mesh sees the network envelope of each request. Application-level tracing with a library like OpenTelemetry sees what happens inside the application while processing that request. Both layers together produce the full picture that serious incident investigation requires. Askan’s DevOps and cloud engineering services help teams integrate service mesh observability with their existing monitoring stack, whether that is Datadog, Grafana, or a managed APM solution.
Making the Decision: A Framework for Your Team
After working through what each mesh offers and what each costs, the decision usually comes down to three questions.
Do you need L7 traffic management that your application cannot own? If you need header-based routing, fault injection for chaos testing, or fine-grained canary traffic splitting that is independent of your deployment tooling, Istio’s traffic management layer is the cleaner solution. If your traffic management needs are limited to weighted splits and basic retries, Linkerd covers that ground with less overhead.
How large is your platform engineering team relative to your service count? A team of two engineers managing 50 services will be stretched thin maintaining Istio. The same team with Linkerd will find the operational surface more manageable. A dedicated platform team of five or more engineers at a 100-plus service organization is the environment where Istio’s depth pays off consistently.
What are your compliance and security requirements? If you operate in a regulated industry and need to demonstrate that all internal service communication is encrypted and that network policy is enforced at the infrastructure level rather than the application level, both meshes satisfy this requirement. Istio’s authorization policy gives you a more expressive control surface for audit evidence, but Linkerd’s automatic mTLS is simpler to explain to an auditor who wants to verify that encryption is on.
Most popular pages

WebAssembly in 2026: Performance, Use Cases and When to Use It in Production
WebAssembly has been in the conversation for nearly a decade, but 2026 is the year more engineering teams are moving it from experimental to...
-
API Gateway Patterns: Rate Limiting, Authentication, and Traffic Management at Scale
An API gateway is where the theoretical neatness of a microservices architecture meets the reality of production traffic. It is the single entry point...
-
GraphQL vs REST vs gRPC: API Architecture Patterns for Microservices in 2026
Choosing an API style is one of those decisions that compounds over time. Pick the wrong one and you end up fighting the framework...

WebAssembly in 2026: Performance, Use Cases and When to Use It in Production
WebAssembly has been in the conversation for nearly a decade, but 2026 is the year more engineering teams are moving it from experimental to...
API Gateway Patterns: Rate Limiting, Authentication, and Traffic Management at Scale
An API gateway is where the theoretical neatness of a microservices architecture meets the reality of production traffic. It is the single entry point...
GraphQL vs REST vs gRPC: API Architecture Patterns for Microservices in 2026
Choosing an API style is one of those decisions that compounds over time. Pick the wrong one and you end up fighting the framework...