



TABLE OF CONTENTS
Zero-Downtime Deployment Strategies: Blue-Green, Canary, and Rolling Updates Compared

Every minute of unplanned downtime carries a measurable cost. For enterprise SaaS platforms, that cost routinely exceeds tens of thousands of dollars per incident. For financial services and healthcare systems, the figure climbs even higher. The pressure to ship features faster while simultaneously protecting uptime has made zero-downtime deployment one of the most critical capabilities a modern engineering team can master.
Three strategies dominate the conversation: Blue-Green deployment, Canary releases, and Rolling updates. Each takes a fundamentally different approach to the core problem of swapping live software without interrupting real users. DevOps engineers, release managers, and SREs need a clear map of when each pattern fits, what it costs to run, and where each one breaks under pressure.
This guide breaks down all three strategies in precise technical terms, compares them across the dimensions that matter most to engineering teams, and provides decision frameworks grounded in real-world production constraints.
Why Zero-Downtime Deployment Is No Longer Optional
The shift from monthly release cycles to continuous delivery has restructured user expectations entirely. Users in 2026 expect instant updates, seamless feature rollouts, and zero maintenance windows. When a competitor ships a fix in hours and you schedule a deployment window at 2:00 AM on a Sunday, you have already lost ground.
The DORA (DevOps Research and Assessment) metrics framework quantifies deployment health across four measurements: deployment frequency, lead time for changes, change failure rate, and mean time to restore. Elite-performing organizations in the DORA report deploy to production multiple times per day with change failure rates below 5%. That level of delivery velocity is only achievable when your deployment mechanism carries no user-visible risk.
Zero-downtime deployment is not simply a reliability practice. It is the infrastructure that enables your release cadence. If you cannot deploy without risk, you will deploy less often. If you deploy less often, you accumulate change and amplify risk further. The pattern compounds against you until every release becomes a high-stakes operation.
The three strategies covered here each solve the same core problem through different trade-offs in cost, complexity, rollback capability, and infrastructure requirements. Understanding those trade-offs is the starting point.
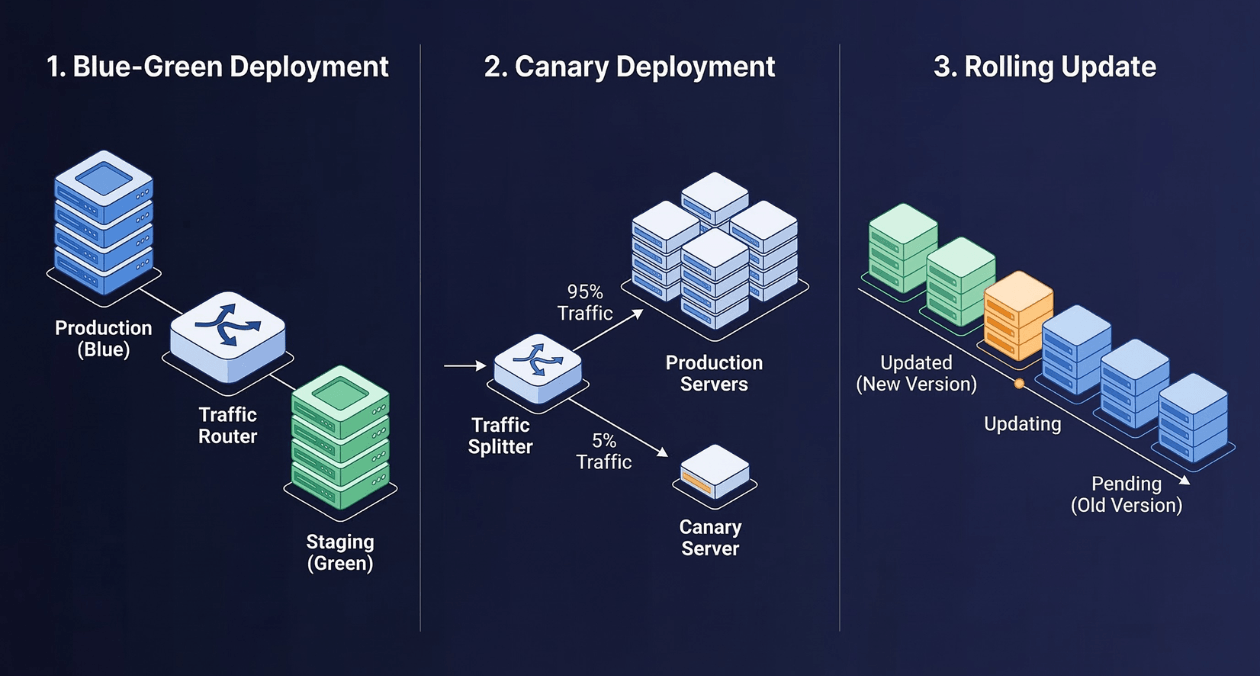
Blue-Green Deployment: Full Environment Mirroring
How Blue-Green Works
Blue-Green deployment maintains two complete, identical production environments at all times. One environment is live and serving user traffic (Blue). The other is idle and receives the new deployment (Green). When the Green environment is fully provisioned, tested, and validated, a load balancer or DNS switch redirects all production traffic from Blue to Green in a single atomic operation.
The former Blue environment remains intact and running after the switch. If the new release reveals a critical defect, operators restore traffic to Blue with a second router update. Rollback time is bounded by the propagation latency of your traffic switch, not by the time required to redeploy software.
Blue-Green: Implementation Requirements
Running Blue-Green at production scale carries specific infrastructure prerequisites that teams often underestimate before committing to the pattern.
| Requirement | Detail |
|---|---|
| Duplicate infrastructure | Two full production stacks running simultaneously during transition |
| Database schema compatibility | Both environments must run against the same database schema simultaneously |
| Traffic switch mechanism | Load balancer, API gateway, or DNS-based switch with fast propagation |
| Session persistence handling | In-flight user sessions must be managed across the switch |
| Smoke test automation | Automated validation suite must run against Green before switching |
Blue-Green: The Database Schema Problem
The most technically demanding aspect of Blue-Green deployment is database migration. If your new release requires a schema change, both Blue and Green must be compatible with that schema during the transition window. This forces a disciplined approach to migrations: additive-only changes during deployment, column removals deferred to a separate cleanup release after the old version is fully retired.
Patterns like Expand-Contract (also known as Parallel Change) formalize this approach. The expand phase adds new columns and tables while the old version still runs. The contract phase removes deprecated structures after the new version has been stable for an agreed period. Teams that skip this discipline encounter the failure mode where Green breaks because Blue is still writing to the old schema during the traffic transition.
Canary Releases: Progressive Traffic Shifting
The Canary Pattern Explained
A Canary release routes a small, controlled percentage of production traffic to the new version while the remaining traffic continues to hit the stable version. The name references the historical practice of sending canaries into coal mines to detect toxic gases before human miners entered. In software, the canary servers absorb risk before the full user base is exposed.
The traffic split begins small, often 1% to 5%, and advances through stages based on observable health signals: error rate, latency percentiles, business metrics like conversion rate, and infrastructure metrics like memory and CPU. When each stage passes its health gates, the traffic percentage increases. When all traffic has migrated successfully, the old version is deprovisioned.
Health Gates and Automated Promotion
Canary releases derive their power from the health gates that govern promotion decisions. Automated canary analysis platforms like Spinnaker, Argo Rollouts, and Flagger query your observability stack continuously and compare canary server metrics against a matched baseline cohort from the stable version.
A well-designed health gate configuration for a Canary release typically evaluates across three metric categories.
| Metric Category | Example Signal | Typical Threshold |
|---|---|---|
| Error Rate | HTTP 5xx percentage | Less than 0.5% above baseline |
| Latency | p99 response time | No more than 10% above baseline |
| Business Metrics | Checkout completion rate | No statistically significant drop |
| Infrastructure | CPU and memory utilization | Within 15% of baseline |
Canary Rollback Mechanics
When a health gate fails at any promotion stage, the automated system halts traffic progression and routes all traffic back to the stable version. Rollback does not require a new deployment or a code operation. It is a traffic routing change, which completes in seconds for in-memory router updates.
The important caveat: canary rollbacks leave behind any data written by users who were routed to the canary version. If those writes are schema-incompatible with the stable version, data integrity requires careful forward-migration planning before any traffic is sent to the canary.
Accelerate Your Deployment Pipeline
Rolling Updates: Incremental Instance Replacement
Rolling Update Mechanics
A Rolling update replaces running instances of the old version with new-version instances progressively across your fleet. Rather than a binary switch (Blue-Green) or a traffic split (Canary), Rolling updates work at the instance level: terminate one old instance, provision one new instance, wait for the new instance to pass health checks, then advance to the next.
Kubernetes manages Rolling updates natively through its Deployment resource. Two parameters control the rollout pace.
| Parameter | Function |
|---|---|
| maxUnavailable | Maximum number of pods allowed to be unavailable during the update |
| maxSurge | Maximum number of extra pods that can exist above the desired replica count |
A common configuration sets maxUnavailable to 0 and maxSurge to 1, which means one new pod is created, validated, then one old pod is terminated. This approach preserves full capacity throughout the rollout at the cost of temporarily running one more pod than the desired count.
Rolling Update Rollback Behavior
Kubernetes Rolling update rollbacks use the same mechanism as the initial update, but in reverse. The rollout history tracks the previous ReplicaSet, and a kubectl rollout undo command initiates a reverse Rolling update, replacing new-version pods with old-version pods at the same controlled pace.
The critical difference from Blue-Green rollback: Rolling update rollback is not instantaneous. It takes time proportional to the number of instances and the maxUnavailable/maxSurge configuration. For a 20-pod deployment with maxSurge of 1, a complete rollback involves 20 sequential replacement cycles.
Direct Comparison: Blue-Green vs Canary vs Rolling Updates
Core Trade-offs at a Glance
| Dimension | Blue-Green | Canary |
|---|---|---|
| Infrastructure Cost | Double (two full stacks) | Moderate (extra canary nodes) |
| Rollback Speed | Seconds (router switch) | Seconds (traffic routing) |
| Traffic Control Granularity | Binary (0% or 100%) | Granular (1% to 100%) |
| Kubernetes Native | Requires external tooling | Requires controller (Argo/Flagger) |
| Database Migration Complexity | High (dual schema support) | High (dual schema support) |
| Dimension | Rolling Update | Best Fit For |
|---|---|---|
| Infrastructure Cost | Low (reuses existing fleet) | Teams with tight infra budgets |
| Rollback Speed | Minutes (reverse rollout) | Workloads with low criticality SLAs |
| Traffic Control Granularity | None (instance-level only) | Stateless, horizontally scaled apps |
| Kubernetes Native | Fully native (Deployment spec) | Cloud-native Kubernetes shops |
| Database Migration Complexity | Moderate (old and new run together) | Apps with additive-safe schema changes |
Failure Mode Comparison
Understanding how each strategy fails under adverse conditions is as important as understanding how they succeed.
| Strategy | Common Failure Mode | Impact Scope |
|---|---|---|
| Blue-Green | Database schema incompatibility during switchover | Full traffic affected if rollback is delayed |
| Canary | Incomplete health gate coverage misses business-layer bugs | Small % of users affected until detection |
| Rolling Update | Partial fleet runs mixed versions longer than expected | All users receive inconsistent behavior |
Session Management Across Deployment Strategies
User sessions represent one of the most technically nuanced challenges in zero-downtime deployment. Sessions that carry state, authentication tokens, or shopping cart data must survive the deployment transition without forcing users to re-authenticate or lose in-progress work.
Externalized session storage is the standard solution. Redis and Memcached serve as session backends shared across both the old and new versions simultaneously. Any instance, regardless of version, can read and write sessions from the shared store. This pattern eliminates in-memory session coupling and makes all three deployment strategies session-safe.
The remaining risk is application-layer session contract changes: if the new version expects a different session data structure than the old version produced, users whose sessions were created by the old version will encounter errors when served by the new version. This requires defensive deserialization code in every new deployment that anticipates both old and new session formats during the transition window.
Accelerate Your Deployment Pipeline
Feature Flags as a Deployment Complement
Feature flags (also called feature toggles) decouple code deployment from feature activation. New code ships to all users in a disabled state. The feature is activated for specific cohorts, percentage groups, or individual accounts through a configuration system without triggering a new deployment.
When combined with zero-downtime deployment strategies, feature flags add a second layer of production control. A canary release can ship the new infrastructure to 10% of traffic, while a feature flag activates the new user-facing functionality for only 2% of accounts within that canary cohort. This two-dimensional control matrix significantly reduces the blast radius of any single release.
| Approach | Deployment Change | Feature Change |
|---|---|---|
| Deploy only | New infrastructure shipped | No user-visible change |
| Feature flag only | No infrastructure change | Feature activates without deploy |
| Deploy + Feature flag | New infrastructure shipped | Feature activates on separate schedule |
LaunchDarkly, Unleash, and Flagsmith are the major commercial and open-source feature flag platforms. Each integrates with observability stacks to enable automatic flag kill-switches when health metrics degrade, creating a deployment safety mechanism that operates at the feature level rather than the infrastructure level.
Observability Requirements for Safe Deployments
Zero-downtime deployment strategies are only as safe as the observability layer that monitors their execution. Without comprehensive metrics, logs, and distributed traces, engineers cannot detect when a deployment is degrading user experience until the impact is large enough to surface in customer reports.
The Four Golden Signals
Google SRE popularized the Four Golden Signals as the minimum observable surface for any production service. These signals are equally applicable as deployment health gates.
| Signal | Deployment Monitoring Role |
|---|---|
| Latency | Detect response time regression in new version vs. baseline |
| Traffic | Validate traffic routing percentages during canary and Blue-Green switches |
| Errors | Detect elevated error rates in new-version instances before full promotion |
| Saturation | Identify resource constraints introduced by new version code or dependencies |
Prometheus and Grafana form the most common open-source observability stack for Kubernetes deployments. Datadog, New Relic, and Honeycomb provide managed alternatives with pre-built deployment correlation dashboards. The deployment-specific requirement is baseline comparison: your monitoring must retain metrics from the prior stable version to serve as a comparison cohort during canary analysis.
Distributed tracing through OpenTelemetry is particularly valuable for microservices deployments where a single user request traverses multiple services. When a new service version introduces latency, traces pinpoint which span in the request graph regressed, reducing the mean time to diagnose from hours to minutes.
GitOps and Deployment Strategy Integration
GitOps defines your infrastructure and deployment configuration as code stored in version-controlled repositories. Deployment operators like Argo CD and Flux reconcile the live cluster state against the desired state defined in Git, automatically applying changes when configuration is merged.
This connects directly to zero-downtime strategies because your Blue-Green, Canary, or Rolling configuration becomes a declarative YAML specification. A Canary rollout defined in Argo Rollouts lives in your Git repository. Promoting from 5% to 25% traffic is a pull request, not a manual operator command. Rollback is a Git revert.
Our earlier coverage of GitOps as the foundation of modern infrastructure management, available at askantech.com/gitops-infrastructure-management, provides the foundational architecture for teams implementing GitOps-driven deployment strategies.
Choosing the Right Strategy for Your Context
Decision Framework
The right strategy depends on four contextual factors: infrastructure budget, rollback time tolerance, database migration complexity, and team operational maturity.
| Context | Recommended Strategy | Rationale |
|---|---|---|
| High SLA, unlimited infra budget | Blue-Green | Instant rollback, full isolation |
| High SLA, complex microservices | Canary with Argo Rollouts | Granular traffic control and auto-analysis |
| Standard SLA, Kubernetes native | Rolling Update | Zero additional tooling or cost |
| Feature-gated releases needed | Any strategy + Feature Flags | Separate infrastructure risk from feature risk |
| Database-heavy application | Blue-Green with Expand-Contract | Schema compatibility is the primary risk |
Combining Strategies in Multi-Tier Architectures
Most production systems benefit from a hybrid approach that applies different strategies to different tiers. Stateless API services are natural candidates for Rolling updates because their horizontal scaling and external session storage make instance replacement safe. Frontend services benefit from Blue-Green because a broken UI is immediately user-visible. Background workers and queue processors often use Canary releases because their processing rate metrics serve as natural health gates.
The organizations that run the most reliable deployments do not pick one strategy and apply it uniformly. They build a deployment strategy map that matches each service tier to the appropriate approach based on that tier’s failure characteristics, traffic sensitivity, and rollback requirements.
Rollback Planning: The Test of a Deployment Strategy
The quality of a deployment strategy is fully revealed by how its rollback behaves under stress. A strategy that deploys smoothly but rolls back slowly is only as good as its worst-case incident response time. Teams that have never practiced rollback in production will discover their blind spots at the worst possible moment.
Rollback drills are the deployment equivalent of disaster recovery exercises. Schedule a monthly rollback drill for each major service: deploy a staged release, verify it is running, then execute a rollback and measure the time from rollback command to full traffic restoration on the previous version. Track this metric over time. Any regression in rollback time indicates a change in your deployment architecture that deserves investigation.
The Accelerate book by Nicole Forsgren, Jez Humble, and Gene Kim documents that high-performing engineering organizations treat Mean Time to Restore (MTTR) as a primary metric precisely because it measures how quickly teams can undo mistakes. Low MTTR is not achieved by preventing all mistakes. It is achieved by building infrastructure that makes undoing mistakes fast and safe.
Progressive Delivery as the Unifying Framework
Progressive Delivery is the framework that unifies Canary releases, Blue-Green deployments, feature flags, and dark launches into a coherent release philosophy. The core principle: never expose all users to unvalidated change simultaneously. Always insert an observation period between deployment and full traffic promotion.
Tools like Argo Rollouts, Flagger, and Spinnaker implement Progressive Delivery as a Kubernetes-native capability. Argo Rollouts defines a Rollout resource that replaces the standard Deployment spec and adds Blue-Green and Canary strategies with integrated metric analysis, traffic weighting, and automated promotion logic.
The CNCF (Cloud Native Computing Foundation) has chartered a Progressive Delivery Working Group that is standardizing the interfaces between deployment controllers, service meshes, and observability backends. This standardization effort, documented at cncf.io, will make Progressive Delivery tooling more interoperable across cloud providers and orchestration platforms over the coming years.
Accelerate Your Deployment Pipeline
Service Mesh Integration for Traffic Management
Service meshes like Istio, Linkerd, and AWS App Mesh provide the traffic management layer that makes Canary releases operationally precise. Without a service mesh, implementing a 3% traffic split requires either custom load balancer configuration or a deployment controller that manipulates replica counts to approximate the desired percentage.
With a service mesh, traffic splitting is configured as a routing rule at the network layer, completely independent of replica counts. A VirtualService in Istio routes exactly 3% of requests matching defined criteria (headers, source service, user attributes) to the canary destination. This precision enables A/B testing workflows where specific user segments are deterministically routed to the new version, producing statistically valid experiment data rather than random traffic sampling.
The practical implication for deployment strategy selection: if your organization is already operating a service mesh, Canary releases become significantly more accessible and precise. If you are deploying on bare Kubernetes without a service mesh, Rolling updates are often the path of least resistance for most services, with Blue-Green reserved for the highest-criticality components that justify the infrastructure duplication cost.
Teams building toward comprehensive deployment automation can also explore how Askan’s full-stack engineering capabilities, described at askantech.com/services, support the infrastructure, toolchain, and application layers that zero-downtime deployment depends on.
Common Implementation Mistakes and How to Avoid Them
| Mistake | Consequence | Prevention |
|---|---|---|
| No smoke tests before Blue-Green switch | Routing to broken Green environment | Automated test suite gate before any traffic switch |
| Insufficient canary health gates | Business regression missed at 5% traffic | Include conversion and business metrics, not just technical metrics |
| Rolling update with in-memory sessions | Users lose sessions mid-deployment | Externalize sessions to Redis before enabling Rolling updates |
| Feature flags never cleaned up | Tech debt accumulates in toggle logic | Flag lifecycle policy with TTL and auto-removal reminders |
| No rollback drill history | Rollback procedure fails under real incident pressure | Monthly rollback drills for critical services |
Measuring Deployment Health Over Time
Deployment strategy effectiveness is not a one-time decision. It requires ongoing measurement to validate that the chosen approach continues to meet your reliability and velocity requirements as your system scales and your team changes.
The four DORA metrics provide the standard measurement framework. Deployment frequency measures how often you deploy to production. Lead time for changes measures the time from code commit to production. Change failure rate measures the percentage of deployments that cause incidents or rollbacks. Mean time to restore measures how quickly you recover when a deployment does cause an incident.
Track these metrics per service, not just organization-wide averages. A globally healthy DORA profile can mask individual services that are deployment bottlenecks for the whole system. Services with high change failure rates are candidates for more conservative deployment strategies, additional automated testing, or architectural refactoring to reduce deployment risk.
Most popular pages
-
Serverless vs Containers: Choosing the Right Compute Model for Your Workload
Every engineering team building on the cloud eventually runs into this question: should this workload run on serverless functions or inside containers. The answer...
-
Postgres vs MySQL in 2026: Which Fits Modern Application Workloads Better
Every couple of years the Postgres versus MySQL debate resurfaces, and 2026 is no different. Teams building new applications still ask the same question...
-
WordPress vs Headless WordPress: When Decoupling Actually Makes Sense
WordPress still runs a massive share of the web, and for good reason. It is fast to launch, familiar to content teams, and backed...
Serverless vs Containers: Choosing the Right Compute Model for Your Workload
Every engineering team building on the cloud eventually runs into this question: should this workload run on serverless functions or inside containers. The answer...
Postgres vs MySQL in 2026: Which Fits Modern Application Workloads Better
Every couple of years the Postgres versus MySQL debate resurfaces, and 2026 is no different. Teams building new applications still ask the same question...
WordPress vs Headless WordPress: When Decoupling Actually Makes Sense
WordPress still runs a massive share of the web, and for good reason. It is fast to launch, familiar to content teams, and backed...