

TABLE OF CONTENTS
Real-Time Data Sync Across Distributed Systems: CRDT, Operational Transform, and Event Sourcing

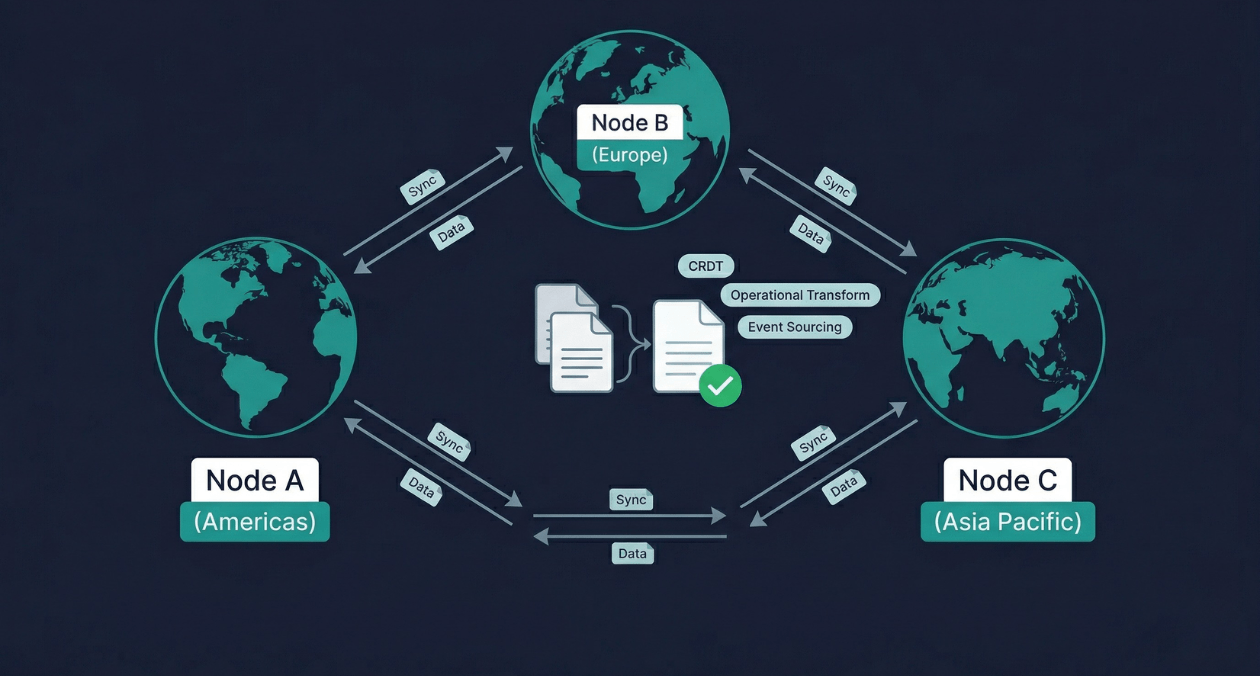
Two users open the same document from different continents. One adds a sentence at the top. The other deletes a paragraph in the middle. Both are offline for thirty seconds. When their connections restore, the application must merge both changes into a single coherent document without losing either user’s work and without asking either of them to resolve a conflict manually. This is the real-time data synchronization problem, and solving it correctly at production scale is one of the most technically demanding challenges in distributed systems engineering.
The same problem appears in different forms across a wide range of applications. A collaborative design tool must merge simultaneous shape edits from multiple designers. A distributed database must reconcile writes that arrived at two geographically separated nodes during a network partition. A mobile application must sync local changes made while offline against changes made by other users on the server during the same period. The users, the data types, and the stakes are different, but the underlying problem is the same: how do you merge concurrent changes to shared state in a way that is correct, fast, and invisible to users?
Three architectural approaches dominate the technical landscape for real-time data synchronization: Conflict-free Replicated Data Types (CRDTs), Operational Transformation (OT), and Event Sourcing with deterministic replay. Each takes a fundamentally different approach to the conflict problem, produces different guarantees, and fits a different set of application requirements. Understanding all three in depth is what enables senior architects, distributed systems engineers, and tech leads to choose the right tool for each synchronization challenge rather than applying a single pattern uniformly across problems it was not designed to solve.
The Core Challenge: Concurrent Writes in Distributed Systems
Distributed systems face a fundamental tension that Eric Brewer formalized in the CAP theorem: a distributed system can guarantee at most two of three properties simultaneously. Consistency means every node sees the same data at the same time. Availability means every request receives a response. Partition tolerance means the system continues operating despite network failures. Because network partitions are not optional in a real distributed system, the practical choice is between consistency and availability when a partition occurs.
Real-time collaborative applications and globally distributed databases generally favor availability during partitions. Users must be able to keep working when their network connection is degraded or temporarily lost. This means accepting that different nodes may have divergent views of the data during a partition. The synchronization problem is therefore not how to prevent divergence but how to resolve it correctly when nodes reconnect.
The naive approach to conflict resolution is last-write-wins: the most recently timestamped write overwrites all others. Last-write-wins is simple to implement but dangerous in practice. It silently discards data. A user who spent twenty minutes editing a document can have their entire session overwritten by another user whose client clock happened to be set a few seconds ahead. For any application where user data has value, last-write-wins is a data loss mechanism dressed up as a conflict resolution strategy.
The three approaches covered in this article are all designed to avoid silent data loss and produce deterministically correct merge results without requiring users to manually resolve conflicts.
Conflict-Free Replicated Data Types (CRDTs)
The Mathematical Foundation
A CRDT is a data structure specifically designed so that concurrent updates from multiple nodes can always be merged into a single consistent state using a mathematical merge function that requires no coordination between nodes and no conflict resolution logic in the application. The key property is that the merge function is commutative, associative, and idempotent. Commutative means the order in which updates are merged does not matter. Associative means updates can be grouped and merged in any order. Idempotent means merging the same update twice produces the same result as merging it once.
These three properties together guarantee that no matter how many times, in what order, or with what delays nodes exchange their state updates, every node that has received the same set of updates will converge to the identical final state. This is strong eventual consistency: not immediate consistency, but a guarantee that all nodes will eventually agree once they have exchanged updates.
CRDTs come in two architectural flavors. State-based CRDTs (CvRDTs) merge entire state objects between nodes. Operation-based CRDTs (CmRDTs) distribute individual operations between nodes rather than full state copies. State-based CRDTs are simpler to implement but can be expensive to transmit when state objects are large. Operation-based CRDTs produce smaller messages but require the communication layer to guarantee that each operation is delivered exactly once.
Common CRDT Types and Their Applications
Different data types require different CRDT implementations because the merge semantics depend on the nature of the data. A counter behaves differently from a set, which behaves differently from a text sequence.
| CRDT Type | Merge Semantics | Common Use Case |
|---|---|---|
| G-Counter (Grow-only) | Each node has its own counter; total is the sum across all nodes | View counts, event tallies, distributed metrics |
| PN-Counter | Two G-Counters: one for increments, one for decrements | Inventory levels, upvote/downvote scores, like counts |
| G-Set (Grow-only Set) | Union of all sets; elements can only be added, never removed | Append-only tag collections, audit membership lists |
| 2P-Set (Two-Phase Set) | Separate add-set and remove-set; removed elements cannot be re-added | Soft-delete collections with immutable removal semantics |
| LWW-Element-Set | Each element carries a timestamp; last-write-wins per element | Shopping cart items, user preference flags |
| OR-Set (Observed-Remove) | Each add assigns a unique tag; remove targets specific tag instances | Collaborative tagging, distributed shopping carts |
| RGA / Logoot / LSEQ | Sequence CRDT with unique position identifiers for each character | Collaborative text editing, real-time document sync |
Sequence CRDTs for Text Collaboration
Text editing is the most challenging CRDT problem because text is an ordered sequence where the meaning of an insertion or deletion depends on the positions of surrounding characters. If two users simultaneously insert characters at the same position in a plain text document, the resulting merged text must interleave the characters in a deterministically defined order that both nodes will independently compute to reach the same result.
The Replicated Growable Array (RGA) assigns a globally unique identifier to each character based on the node ID and a logical timestamp at the time of insertion. The merge function sorts characters by these identifiers, producing a consistent total ordering across all nodes. Logoot and LSEQ take a fractional position approach, assigning each character a position between the positions of its left and right neighbors. Both approaches guarantee that all nodes arrive at the same character ordering without coordination, but they differ in memory overhead and the complexity of the identifier allocation strategy.
Yjs, a widely used open-source CRDT library for JavaScript, implements a variant of the YATA (Yet Another Transformation Approach) algorithm that achieves better performance than RGA for typical collaborative editing workloads. Yjs powers the real-time collaboration features in tools like Hocuspocus, Tiptap, and BlockSuite, and its protocol has been adopted by several commercial collaborative editing platforms because of its proven performance characteristics at scale.
Implement Production-Grade Real-Time Sync for Your Platform
Operational Transformation (OT)
The OT Model
Operational Transformation was the first widely deployed approach to real-time collaborative text editing, introduced in the Jupiter collaboration system at Xerox PARC in 1989 and subsequently adopted by Google Docs, Apache Wave, and several other collaborative platforms. Where CRDTs embed conflict resolution into the data structure itself, OT resolves conflicts by transforming operations against each other before applying them.
The central concept in OT is the transform function. When two concurrent operations are produced independently, they are defined relative to the same document state at the time they were created. If Operation A (insert ‘hello’ at position 5) and Operation B (delete character at position 3) were both produced against document version 10, applying A first changes the document, which means B’s position reference is now incorrect. The OT transform function takes A and B and produces a transformed B’ that accounts for the effect of A, so that applying B’ after A produces the same result as applying A’ after B.
This transformation must satisfy two properties to guarantee consistency. The first is convergence: if two clients apply the same set of operations in different orders, they must arrive at the same final state. The second is intention preservation: each operation must have the same semantic effect regardless of the order in which it is applied, so that an insert at position 5 still inserts at the correct logical position even after other operations have shifted character positions.
OT vs CRDT: Where Each Excels
| Dimension | Operational Transform | CRDT |
|---|---|---|
| Server requirement | Typically requires a central server to serialize operations | Fully peer-to-peer; no central coordinator required |
| Algorithm complexity | Transform functions are complex; correctness proofs are difficult | Mathematically proven convergence; simpler application logic |
| Memory overhead | Operations only; no persistent position identifiers | Each character carries a unique identifier; higher memory use |
| Network model | Works well with central server serialization | Works well in peer-to-peer and offline-first scenarios |
| Real-world adoption | Google Docs, Etherpad, Codox | Yjs (Notion, Gitbook), Automerge, Fluid Framework |
OT’s requirement for a central server to impose a global ordering of operations is both its strength and its constraint. The server simplifies the transformation logic because each client always receives operations in a consistent global order. But it creates a single point of failure and a scaling bottleneck for applications that need to support very high concurrency or offline operation without server connectivity. Google Docs handles this by maintaining a server-side operation log that acts as the canonical ordering authority.
CRDTs have largely displaced OT for new collaborative editing implementations because their peer-to-peer operation model fits the offline-first and edge computing architectures that have become standard in 2026. However, OT remains the appropriate choice for systems already built on the OT model and for applications where a central server is present and the additional CRDT memory overhead would be prohibitive.
Event Sourcing for Distributed Data Sync
Event Sourcing as a Synchronization Architecture
Event sourcing approaches the synchronization problem from a different angle than CRDTs or OT. Rather than resolving conflicts between concurrent state changes, event sourcing stores every change as an immutable ordered event in an append-only log. The current state of any entity is always derived by replaying its event log from the beginning. Synchronization between distributed nodes becomes the problem of replicating and ordering event logs, rather than the problem of merging divergent state.
When two nodes diverge during a network partition, each node continues appending events to its local log. When the partition heals, the nodes exchange their event logs and establish a consistent total ordering of all events across both logs. Each node then replays the merged event log to derive the correct current state. The key insight is that an event log is easier to merge than mutable state because each event is immutable and identified by a unique logical timestamp, even if the physical arrival times differ between nodes.
The challenge is establishing a consistent total ordering of events produced by different nodes at approximately the same time. Lamport clocks assign a logical timestamp to every event that is greater than all previously known timestamps at the producing node, regardless of physical clock differences. Vector clocks extend this to track causal relationships: an event that causally follows another event will always have a higher vector clock value on the producing node’s dimension, allowing the merge function to detect concurrent events that have no causal relationship and apply a deterministic tie-breaking rule to order them consistently.
Event Sourcing with Apache Kafka for Distributed Sync
Apache Kafka’s partitioned log architecture maps naturally onto the event sourcing synchronization model. Each entity type or aggregate root has its own Kafka topic partition. Events for a given entity are always written to the same partition, which guarantees ordering for that entity. Consumers on all nodes read from the same Kafka topic and apply events in the same order, converging to the same state without any peer-to-peer coordination between consumer nodes.
This architecture, which the Kafka community calls the shared log or event streaming backbone pattern, is the basis for the event-driven architecture approach covered in the March 25 article on event-driven architecture patterns. When applied specifically to state synchronization, Kafka’s durable ordered log becomes the synchronization medium: any node that has consumed the same set of events from the same partitions is guaranteed to hold the same derived state.
The limitation is that Kafka requires all nodes to be connected to the same cluster for synchronization. For edge nodes, mobile clients, or geo-distributed deployments where nodes must operate independently for extended periods, a pure Kafka-based approach requires supplementing with a local event log at each node and a reconciliation protocol that merges local logs with the central Kafka log when connectivity is restored.
Hybrid Approach: Event Sourcing with CRDT State
The most robust synchronization architectures for modern distributed applications combine event sourcing for audit trail and replay with CRDT semantics for the state representation. Each event that modifies shared state carries a CRDT operation rather than a raw state delta. The event log provides ordering, durability, and replay capability. The CRDT semantics guarantee that applying the same set of events in any order produces the same final state, eliminating the ordering-sensitivity that makes pure event sourcing fragile when log merging produces ambiguous orderings.
This hybrid approach is used in Figma’s multiplayer synchronization layer, where each design operation is stored as an event and the canvas state is represented as a tree of CRDT-like objects that can absorb concurrent edits without coordination. It is also the foundation of the Ditto platform, which provides offline-first CRDT synchronization for mobile applications with eventual consistency guarantees even when devices are offline for days.
Implement Production-Grade Real-Time Sync for Your Platform
Consistency Models and Their Practical Implications
Understanding which synchronization technique to apply requires clarity about which consistency model your application requires. The consistency model defines what guarantees users have about the state they observe across nodes.
| Consistency Model | Guarantee | Best Fit |
|---|---|---|
| Strong consistency | All nodes see the same state at the same time after every write | Financial transactions, inventory deductions, unique constraint enforcement |
| Sequential consistency | All nodes see operations in the same global order, though not necessarily in real time | Leaderboard updates, ordered event logs with global sequencing |
| Causal consistency | Causally related operations are seen in order; concurrent operations may be seen differently | Social feeds, comment threads, document collaboration |
| Eventual consistency | All nodes converge to the same state after all updates are exchanged; no ordering guarantee | Shopping carts, user preference sync, distributed counters |
| Strong eventual consistency | Deterministic convergence guaranteed by CRDT merge semantics | Collaborative text editing, offline-first sync |
CRDTs provide strong eventual consistency. OT provides sequential consistency within a session when a central server serializes operations. Event sourcing with Kafka provides sequential consistency across all consumers of the same partition. The choice between them is therefore partly a choice between consistency models: if causal consistency is sufficient, CRDTs are the most operationally simple option. If sequential consistency is required, OT with central serialization or Kafka-based event sourcing are the appropriate approaches.
Offline-First Architecture and Sync on Reconnect
Offline-first applications treat the local device as the primary data store and the server as a synchronization peer rather than the authoritative source. Users interact with local data at full speed regardless of network availability. When connectivity is restored, the local changes are merged with remote changes using whichever synchronization technique the application implements.
CRDTs are particularly well-suited for offline-first architectures because their merge function requires no server coordination. A mobile application can use Automerge or Yjs to maintain a local CRDT document, record all user operations against it while offline, and merge those operations with the server’s version when the connection is restored. The merge is deterministic and produces no conflicts regardless of how long the device was offline or how many other users made concurrent changes.
PouchDB with CouchDB replication, Realm Sync (now Atlas Device Sync from MongoDB), and PowerSync are production offline-first synchronization platforms that implement either CRDT semantics or revision-based conflict resolution for mobile applications. Each handles the synchronization protocol, conflict detection, and network resilience, allowing application developers to focus on data modeling rather than synchronization mechanics.
The database selection decisions that underpin offline-first architectures, including the trade-offs between document databases and relational databases for mobile sync scenarios, are covered in depth in the March 23 article on PostgreSQL vs MySQL vs MongoDB as part of the Database Architecture and Performance series.
Vector Clocks, Lamport Clocks, and Hybrid Logical Clocks
Physical clocks across distributed nodes are unreliable for establishing event ordering. Clock skew, NTP synchronization delays, and leap second handling mean that comparing physical timestamps across nodes produces incorrect orderings. The distributed systems field has developed three logical clock approaches that provide correct event ordering without depending on synchronized physical clocks.
Lamport clocks are the simplest approach. Each node maintains a counter. On every event, the counter increments. On every message send, the current counter value is attached. On message receipt, the receiver sets its counter to the maximum of its own value and the received value plus one. Lamport clocks guarantee that if event A causally precedes event B, then A’s timestamp is less than B’s timestamp. They do not guarantee the converse: two events with the same Lamport timestamp may be concurrent or may have a causal relationship that the single integer cannot capture.
Vector clocks solve this by maintaining one counter per node in a vector. Each event increments only the local node’s dimension of the vector. Two vector clock values are comparable if one dominates the other component-wise. If neither dominates, the events are concurrent. This allows the synchronization layer to detect true concurrency and apply CRDT merge semantics or a deterministic tie-breaking function precisely to the events that are genuinely concurrent, rather than applying it unnecessarily to sequentially ordered events.
Hybrid Logical Clocks (HLCs), developed by Sandeep Kulkarni and used in CockroachDB and YugabyteDB, combine the human readability of physical timestamps with the correctness of logical clocks. An HLC is a pair of a physical timestamp and a logical counter. The physical component keeps the clock close to wall clock time. The logical component increments to break ties when physical timestamps are identical. HLCs provide the ordering guarantees of vector clocks while remaining compatible with time-based queries and retention policies that depend on wall clock time.
Practical Implementation Patterns
Choosing the Right Approach for Common Scenarios
| Scenario | Recommended Approach | Key Reason |
|---|---|---|
| Collaborative text editor (multi-user, real-time) | CRDT (Yjs or Automerge) | Peer-to-peer, offline-capable, no transform function complexity |
| Collaborative text editor (centralized, server-authoritative) | OT (e.g., ShareDB / sharedb) | Central server simplifies transform logic; proven at scale (Google Docs model) |
| Distributed database with geo-replication | Event sourcing with vector clocks | Causal ordering without CRDT overhead; Kafka log as sync medium |
| Offline-first mobile app with server sync | CRDT (Automerge / Realm Sync) | Deterministic merge on reconnect without user-facing conflicts |
| Shopping cart across browser tabs and devices | LWW-Element-Set CRDT or revision-based | Simple merge semantics; last-added-item wins per product is acceptable |
| Collaborative spreadsheet with formula dependencies | OT with dependency tracking | Formula recalculation order matters; CRDT ordering alone is insufficient |
Libraries and Platforms Worth Knowing
Yjs is the most production-battle-tested CRDT library for JavaScript and TypeScript applications. Its network-agnostic design allows it to work over WebSocket, WebRTC, or any other transport. The Hocuspocus server provides a ready-made Yjs backend that handles persistence, awareness (showing which users are currently active), and multi-document management. For teams building collaborative tools without wanting to implement the synchronization protocol from scratch, Yjs with Hocuspocus is the fastest path to production.
Automerge is a CRDT library that operates on JSON documents rather than text sequences, making it a better fit for applications that need to synchronize structured data across nodes. Its Rust core with JavaScript and Swift bindings makes it viable for both web and mobile applications, and its local-first software philosophy aligns with the emerging local-first application architecture pattern championed by the Ink and Switch research group.
ShareDB is the leading open-source OT framework for Node.js. It provides a client-server OT implementation with pluggable backend adapters for PostgreSQL, MongoDB, and Redis. ShareDB is the engine behind several production collaborative editing tools and remains the preferred OT implementation for server-authoritative architectures where the central ordering guarantee of OT is a feature rather than a limitation.
The full-stack software engineering capabilities at Askan Technologies include distributed systems architecture design, real-time collaboration feature implementation using Yjs, Automerge, and ShareDB, and event sourcing pipeline development using Apache Kafka and EventStoreDB. Teams building applications that require real-time synchronization at production scale can engage our senior distributed systems engineers to validate architecture choices and accelerate implementation.
Operational Considerations for Production Sync Systems
Real-time synchronization systems introduce operational complexity that pure request-response systems do not face. WebSocket connection management at scale requires careful load balancer configuration: connections must be sticky to the same server instance because the synchronization state accumulated on one server cannot be instantly transferred to another. AWS ALB, NGINX, and HAProxy all support WebSocket-aware sticky sessions, but the application must handle reconnection gracefully when a server instance fails and the client must reconnect to a different server with potentially stale synchronization state.
CRDT document size grows over time because unique character identifiers are never removed from the document, even when the characters they represent have been deleted. A heavily edited document in Yjs or Automerge accumulates tombstone entries for deleted characters that expand the CRDT state without corresponding user-visible content. Periodic compaction operations merge and clean the internal CRDT state to keep document sizes manageable, but compaction must be coordinated across all connected clients to avoid creating divergent compacted states that cannot be merged.
Monitoring synchronization systems requires metrics beyond the standard web service observability stack. Key signals include synchronization lag per client (how far behind each client is from the authoritative state), operation queue depth (how many pending operations are waiting to be applied), conflict rate (how often the synchronization layer encounters true concurrent conflicts that require merge logic), and reconnection frequency (high reconnection rates indicate network instability that will stress the sync protocol). The observability principles and tooling covered in the March 18 article on building observable systems apply directly to these sync-specific signals.
Implement Production-Grade Real-Time Sync for Your Platform
Most popular pages

Data Warehouse vs Data Lake vs Data Lakehouse: Analytics Infrastructure for 2026
Every organization that generates data eventually faces a version of the same question: where should that data live so that the people and systems...
-
Event-Driven Architecture: When to Use Message Queues, Event Streams, and Pub/Sub
Synchronous request-response is the default communication model for most web applications. A service calls another service, waits for the response, and continues. At low...
-
Database Scaling Strategies: From 1K to 10M Queries Per Second
Most databases start their lives handling a few hundred queries per second against a schema designed in a weekend. The first thousand users arrive...

Data Warehouse vs Data Lake vs Data Lakehouse: Analytics Infrastructure for 2026
Every organization that generates data eventually faces a version of the same question: where should that data live so that the people and systems...
Event-Driven Architecture: When to Use Message Queues, Event Streams, and Pub/Sub
Synchronous request-response is the default communication model for most web applications. A service calls another service, waits for the response, and continues. At low...
Database Scaling Strategies: From 1K to 10M Queries Per Second
Most databases start their lives handling a few hundred queries per second against a schema designed in a weekend. The first thousand users arrive...