

TABLE OF CONTENTS
GitOps: The Future of Infrastructure Management and Continuous Deployment

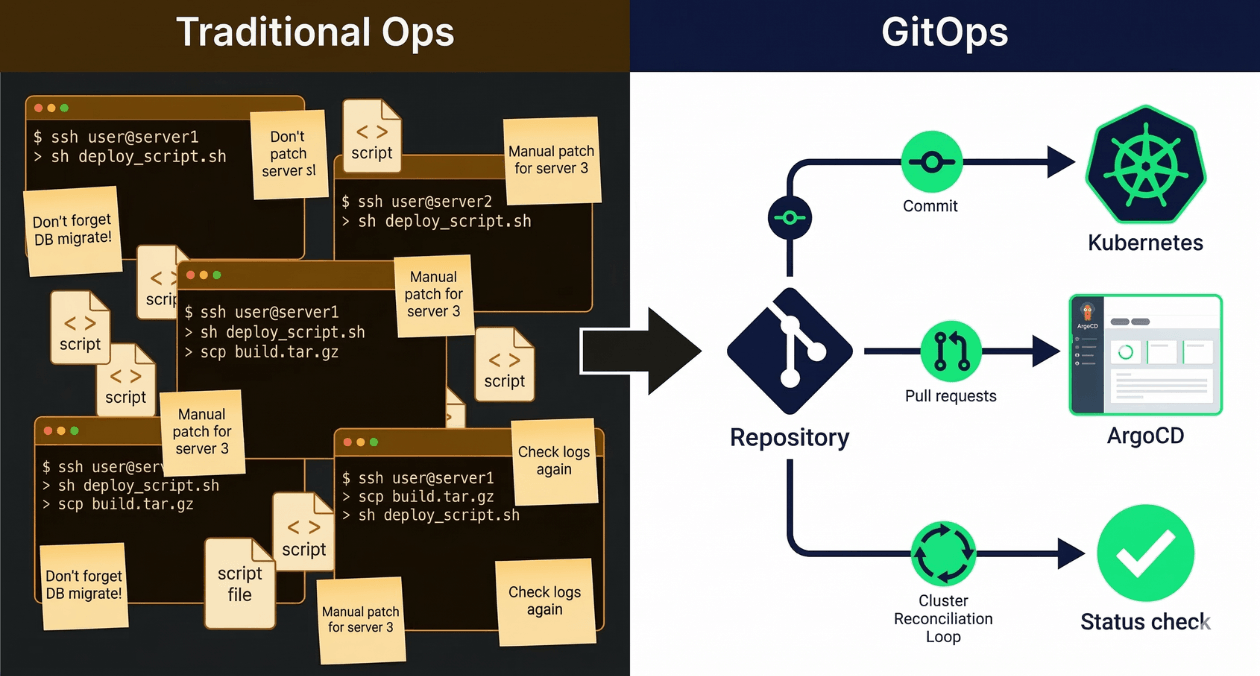
Every engineering team eventually reaches the point where their deployment process becomes a liability. Someone knows the magic sequence of commands. Rollbacks require tribal knowledge. The state of production is documented nowhere except in the memory of the engineer who last touched it. GitOps is the operational model that resolves this class of problem by treating infrastructure state the same way application code is treated: as a versioned artifact that lives in a repository, reviewed through pull requests, and applied automatically by a reconciliation system.
This article covers what GitOps means in practice, how it differs from traditional CI/CD pipelines, which tools dominate the space, how to structure your repositories, and what the adoption path looks like for teams at different stages of infrastructure maturity.
What GitOps Actually Means
The term GitOps was coined by Weaveworks in 2017, but the underlying idea is straightforward. Git becomes the single source of truth for both application code and infrastructure configuration. A reconciliation agent running inside your cluster continuously compares the desired state declared in Git against the actual state running in the cluster. When they diverge, the agent acts to bring the cluster back into alignment, either by applying new changes or by reverting unauthorized drift.
This produces three properties that traditional push-based deployment pipelines cannot guarantee on their own.
| Property | What It Means in Practice |
| Declarative | Infrastructure is described as desired state, not as a sequence of imperative commands |
| Versioned and auditable | Every change to infrastructure state is a Git commit with an author, a timestamp, and a diff |
| Continuously reconciled | Drift from the declared state is detected and corrected automatically without manual intervention |
The last property is what separates GitOps from simply storing your Kubernetes manifests in a repository. Storing files in Git without a reconciliation loop gives you version history but does not prevent drift. A runbook edit applied directly with kubectl during an incident still leaves your cluster in a state that does not match Git. GitOps closes that gap.
GitOps vs Traditional CI/CD: Where the Model Shifts
Traditional CI/CD pipelines are push-based. A commit triggers a pipeline that runs tests, builds an artifact, and then pushes that artifact into the target environment using deployment credentials stored in the CI system. The CI system reaches into the cluster and makes changes.
GitOps flips this model. The CI system builds artifacts and updates image tags or manifest references in the Git repository. A separate reconciliation agent running inside the cluster pulls those changes from Git and applies them. The cluster never exposes credentials to an external system. The CI pipeline has no write access to the cluster at all.
| Dimension | Push-Based CI/CD | GitOps Pull-Based |
| Deployment trigger | CI pipeline pushes to cluster | Reconciler pulls from Git |
| Cluster credentials | Stored in CI system | Never leave the cluster |
| Drift detection | None by default | Continuous, automatic |
| Rollback mechanism | Re-run old pipeline or manual | Revert a Git commit |
| Audit trail | CI logs (often ephemeral) | Git history (permanent) |
The security improvement is significant for teams operating in regulated environments or handling customer data. Eliminating outbound cluster credentials from the CI system reduces the blast radius of a compromised pipeline substantially.
ArgoCD and Flux: The Two Dominant GitOps Engines
Two open-source tools have become the standard implementations of the GitOps reconciliation pattern for Kubernetes: ArgoCD and Flux. Both are CNCF projects. Both watch a Git repository and reconcile cluster state. The differences are in operator experience, architectural philosophy, and ecosystem integrations.
| Criterion | ArgoCD | Flux |
| UI | Rich web UI included out of the box | No built-in UI; integrates with Weave GitOps |
| Architecture | Single controller with centralized management | Modular controllers (source, kustomize, helm, etc.) |
| Multi-tenancy | Application-level RBAC built in | Requires careful namespace and RBAC design |
| Bootstrapping | ArgoCD app-of-apps pattern | flux bootstrap command per cluster |
ArgoCD is often the faster path to a working demo because its web interface makes the reconciliation state immediately visible. Teams new to GitOps find it easier to understand what is happening when they can see application sync status, resource health, and diff views in a browser. The ArgoCD documentation covers installation to production hardening comprehensively.
Flux suits teams that prefer a CLI-driven, Kubernetes-native operator model. Its modular design means you install only the controllers you need. The Flux Image Automation controller handles automatic image tag updates, closing the loop between a container registry and your Git repository without external tooling.
Both tools support Helm and Kustomize as rendering engines for your manifests, which means you are not forced to choose between them and your existing packaging approach.
Want to implement GitOps for your Kubernetes infrastructure? Talk to the Askan platform engineering team.
Repository Structure: The Mono-Repo vs Multi-Repo Decision
How you organize your Git repositories for GitOps has long-term consequences for team autonomy, access control, and pipeline complexity. Two broad patterns exist: the mono-repo and the multi-repo approach.
In a mono-repo structure, all environment configurations for all services live in a single repository. This makes it easy to see the full state of every environment in one place and to enforce cross-service policies at the repository level. The tradeoff is that a single merge to main can trigger reconciliation across many services simultaneously, and access control becomes coarser than some teams want.
In a multi-repo structure, each service or team owns its configuration repository. Application code and infrastructure config can either share a repository or live separately. This gives teams full ownership of their deployment pipeline without touching a shared resource, but it increases the overhead of coordinating changes that span multiple services.
| Structure | Best Suited For |
| Mono-repo | Small to medium platform teams, strong central governance, fewer than 30 services |
| Multi-repo | Large organizations, strict team ownership boundaries, many independent services |
| Hybrid (app code + config split) | Teams wanting application and deployment concerns versioned independently |
A practical starting point for most teams is a dedicated infrastructure repository separate from application code, with a directory structure that mirrors environments. A top-level directory per environment (dev, staging, production) containing subdirectories per service prevents accidental promotion of configuration and makes the promotion path explicit.
Handling Secrets in a GitOps World
Storing secrets in a Git repository is not acceptable regardless of whether the repository is private. GitOps creates a natural tension here because the goal is to have Git represent everything, but plaintext credentials in version history are a permanent liability.
Three patterns address this cleanly.
Sealed Secrets (Bitnami): A controller running in the cluster holds a private key. You encrypt secrets locally using the matching public key into a SealedSecret custom resource. The SealedSecret is safe to commit. The controller decrypts it at deploy time. Rotation requires generating a new encrypted value and committing it.
External Secrets Operator: Manifests in Git reference secret paths in an external store such as AWS Secrets Manager, HashiCorp Vault, or Google Secret Manager. The operator fetches the actual secret values at runtime and creates Kubernetes Secret objects. The Git repository never contains secret material at all.
SOPS (Secrets OPerationS): Mozilla’s SOPS tool encrypts specific fields within YAML files using KMS keys (AWS KMS, GCP KMS, or age keys). The encrypted file is committed to Git. Flux has native SOPS decryption support, making this a zero-additional-controller option for Flux users.
External Secrets Operator is the most operationally mature choice for teams already using a secrets manager, because it keeps secret rotation entirely outside the Git workflow. You rotate the value in Secrets Manager and the operator picks up the change on its next sync cycle without any Git commit required.
Progressive Delivery on Top of GitOps
GitOps establishes the mechanism for getting a desired state into a cluster. Progressive delivery extends that with controls over how much traffic a new version receives and how fast that traffic shifts. Flagger is the most widely used operator for this, and it integrates directly with ArgoCD and Flux.
Flagger watches a Kubernetes Deployment and automates canary releases, blue-green deployments, and A/B tests. When a new image tag is reconciled into the cluster, Flagger takes over the traffic shifting, monitors metrics from Prometheus or Datadog, and either promotes the new version to full traffic or rolls it back based on thresholds you define. The rollback is a Git commit away regardless of what Flagger decides, because the desired state in Git remains the authoritative record.
| Delivery Strategy | How Flagger Handles It |
| Canary | Gradually shifts traffic percentage to new version while monitoring error rate and latency |
| Blue-Green | Stands up the new version in full, then shifts all traffic at once after a configurable analysis window |
| A/B Testing | Routes traffic based on HTTP headers or cookies to compare two versions with specific user segments |
Drift Detection and Why It Matters More Than You Think
In a mature GitOps setup, the reconciler runs continuously and any diff between cluster state and Git state triggers an alert or an automatic correction. This changes the operational culture in a meaningful way: engineers stop thinking of the cluster as something they directly manage and start thinking of Git as the interface through which all changes flow.
Drift can originate from several sources. An engineer applies a kubectl patch during an incident and forgets to update the manifest. A Helm chart upgrade mutates a ConfigMap in a way that does not match the declared values. A custom controller modifies a resource as part of its own logic. All of these are drift. GitOps reconciliation catches and corrects them on the next sync cycle.
Some teams configure their GitOps tooling in monitoring-only mode initially, where drift is detected and reported but not automatically corrected. This is a sensible transition step. It builds confidence that the reconciler understands your workloads correctly before you enable automatic self-healing on production workloads.
Structuring the Promotion Pipeline Across Environments
A GitOps promotion pipeline moves a change from development through staging to production through Git operations, not through pipeline scripts that push directly to each environment. The mechanics depend on whether you use Kustomize or Helm for manifest rendering.
With Kustomize, the base manifests define the common configuration, and each environment’s overlay directory patches the specific differences such as replica counts, resource limits, and image tags. Promoting from staging to production means updating the image tag in the production overlay and merging that change, which the reconciler picks up and applies.
With Helm, each environment has its own values file. Promotion means updating the image tag or chart version in the production values file. Tools like Renovate Bot or Flux’s Image Automation can automate the image tag update step, creating a pull request when a new image is pushed to the registry and closing the automation loop.
Regardless of the rendering approach, requiring a pull request review for production promotions preserves a human checkpoint in the deployment process. This is not a contradiction of GitOps automation. It is the access control layer that GitOps makes straightforward to enforce. For teams scaling their DevOps practice, Askan’s infrastructure and cloud engineering services help design promotion pipelines that balance automation with governance requirements.
Observability for Your GitOps Pipeline
A GitOps pipeline introduces new failure modes that traditional CI/CD observability does not cover. A sync failure in ArgoCD or Flux may not surface in your existing alerting unless you instrument it specifically. The reconciler might fail to apply a manifest due to a webhook validation rejection, a resource quota limit, or a CRD version mismatch. Without alerts on these conditions, your deployment appears to succeed from the CI perspective while the cluster quietly ignores the change.
Both ArgoCD and Flux expose Prometheus metrics. ArgoCD emits metrics on application sync status, health status, and reconciliation latency. Flux emits metrics per controller on reconciliation duration and error counts. Adding dashboards for these metrics in Grafana and alerting on sync failures and health degradations is a minimum viable observability setup for a production GitOps installation. The CNCF’s GitOps working group publishes guidance on observability practices and principles that is worth reviewing as your practice matures.
Adopting GitOps Incrementally
Teams that attempt a full GitOps migration of all workloads simultaneously often struggle with the scope. The more effective path starts with a single non-production cluster or a single low-risk service.
- Install ArgoCD or Flux in a development cluster.
- Move the manifests for one service into a dedicated Git repository or directory.
- Configure the reconciler to watch that path and apply changes automatically.
- Verify that a Git commit causes the cluster to update without manual intervention.
- Add drift detection alerts and confirm they fire when a manual kubectl change is made.
- Extend to staging and then production once the team trusts the reconciliation behavior.
- Add image automation so that new image tags trigger pull requests rather than requiring manual updates.
Each step is independently valuable. Even stopping at step four, where Git drives deployments for one service, is a meaningful improvement over fully manual processes. The full value of continuous reconciliation, drift detection, and automated promotion accumulates as more workloads are brought under GitOps management.
Common Pitfalls and How to Avoid Them
| Pitfall | How to Handle It |
| Storing plaintext secrets in Git | Use External Secrets Operator, Sealed Secrets, or SOPS from the start |
| No pull request gate on production | Require PR review for production overlay changes; use branch protection rules |
| Reconciler in sync-only mode with no drift alerts | Enable Prometheus metrics and alert on sync failures and health degradations from day one |
| Mixing imperative kubectl commands with GitOps | Establish a team norm: all changes go through Git; direct kubectl access to production is break-glass only |
| Single large repo with no clear directory ownership | Define directory ownership with CODEOWNERS files so the right team reviews changes to their services |
Where GitOps Fits in the Broader Platform Engineering Picture
GitOps is one layer of a platform engineering stack, not the complete solution. It handles the deployment and reconciliation layer. It does not replace a service mesh for traffic management, a secrets manager for credential lifecycle, or a policy engine like OPA Gatekeeper for admission control. In a mature internal developer platform, GitOps is the delivery mechanism that carries the output of all these other systems into the cluster in a controlled, auditable way.
For engineering teams building or modernizing their platform practices, the combination of GitOps with infrastructure as code tooling such as Terraform or Pulumi for cluster provisioning, and with a policy-as-code framework for compliance, produces an infrastructure that is fully reproducible from a blank-slate cloud account. Askan’s platform engineering and DevOps consulting engagements help teams design this full stack and implement it at a pace that their existing operations team can absorb without disrupting production services.
Most popular pages

WebRTC and Real-Time Communication: Building Video Chat and Collaboration Features
Real-time communication has moved from a premium feature into a baseline expectation. Users want to speak, see, and collaborate without leaving the application they...
-
Offline-First Mobile Architecture: Building Apps That Work Without Internet
Most apps are built with the assumption that the internet is always there. Your code fires a request, the server responds, and the interface...
-
Progressive Web Apps in 2026: When PWAs Beat Native Apps for Enterprise
Progressive Web Apps have evolved from experimental technology to enterprise-grade platforms. In 2026, PWAs deliver capabilities that were exclusive to native apps just three...
WebRTC and Real-Time Communication: Building Video Chat and Collaboration Features
Real-time communication has moved from a premium feature into a baseline expectation. Users want to speak, see, and collaborate without leaving the application they...
Offline-First Mobile Architecture: Building Apps That Work Without Internet
Most apps are built with the assumption that the internet is always there. Your code fires a request, the server responds, and the interface...

Progressive Web Apps in 2026: When PWAs Beat Native Apps for Enterprise
Progressive Web Apps have evolved from experimental technology to enterprise-grade platforms. In 2026, PWAs deliver capabilities that were exclusive to native apps just three...