



TABLE OF CONTENTS
Async Communication in Engineering Teams: When Fewer Meetings Produce Better Code


There is a version of the engineering day that many developers know well. The calendar is split into one-hour blocks. Stand-ups run long. Syncs spawn follow-up syncs. By the time an afternoon of uninterrupted work becomes possible, mental energy is already depleted. The code that gets written in those conditions tends to reflect it.
Async-first communication is not a new concept, but engineering organisations are increasingly treating it as a deliberate strategy rather than a default result of remote work. Teams that structure their communication around written, time-shifted exchanges rather than real-time synchronisation consistently report fewer context-switch interruptions, better documentation hygiene, and, perhaps most importantly, better code. This article looks at how that shift happens in practice, what makes it work, and where it genuinely should not be applied.
The engineering team at Askan Technologies works with distributed development environments daily, and the patterns described here reflect what actually holds up under pressure, not what sounds tidy on a blog post.
Why Meeting-Heavy Engineering Cultures Underperform
The problem with meetings in engineering contexts is not that they are inherently bad. It is that they carry a cost that rarely shows up on the calendar invite. Every synchronous meeting pulls an engineer out of deep work, and re-entering that state takes time. Research consistently shows that recovery from an interruption in complex cognitive work takes significantly longer than the interruption itself. For engineering teams working on architecture decisions, debugging, or complex feature implementation, a 30-minute meeting mid-morning can functionally cost two hours of productive output.
The second problem is information loss. When decisions are made verbally in a meeting and not recorded properly, the context disappears with the call. New team members have no access to the reasoning behind choices. Engineers who were absent from the call rely on secondhand summaries. Code reviews reference decisions that nobody can trace back to a documented discussion. Over time, this creates what some teams call organisational amnesia, where the institutional knowledge of why things were built a certain way lives only in the heads of the people who happened to be in the room.
This is not a problem unique to any particular type of company. Teams using Node.js, React, and modern cloud architectures face it just as much as those working in legacy systems. The tooling changes, the communication challenge does not.
What Async Communication Actually Means in Practice
Async communication does not mean slow communication, and it does not mean zero meetings. It means that the default mode of information exchange is written and structured, with real-time conversation reserved for situations that genuinely benefit from it.
In practice, this looks like the following. A developer working on a feature writes a detailed description of the problem they are solving before they start coding. An architecture decision gets captured in a short written document before it gets implemented. A code review comment is written with enough context that the person reading it tomorrow morning does not need to ask three follow-up questions. A production incident gets documented as it unfolds, so the post-mortem is a matter of cleaning up notes rather than reconstructing events from memory.
The common thread is that the communication creates a record. It is consumable at the reader’s pace, searchable later, and does not require both parties to be online at the same moment.
The Formats That Make Async Engineering Communication Work
Not all written communication is equally effective. A Slack message that says “quick question” followed by silence for four hours is worse than a meeting. The formats that support genuine async-first engineering culture share a few characteristics: they provide enough context for the reader to respond without needing to ask clarifying questions, they are structured consistently enough that readers know what to expect, and they are stored somewhere discoverable.
Architecture Decision Records
An Architecture Decision Record, commonly abbreviated as ADR, is a short document that captures a technical decision, the context in which it was made, the options that were considered, and the reasoning behind the choice. Teams that use ADRs consistently find that onboarding new engineers is faster, code review discussions are more grounded, and revisiting past decisions requires reading a document rather than asking whoever was around at the time.
ADRs do not need to be long. A single-page format covering the status of the decision, the context, the decision itself, and the consequences is enough. Storing them in the same repository as the code they relate to keeps them discoverable. The GitHub documentation on ADR practices provides a well-maintained set of templates and examples that teams can adapt without starting from scratch.
Written RFC Processes for Significant Changes
A Request for Comments, or RFC, is appropriate when a change is significant enough that it deserves team input before implementation begins. Rather than calling a meeting to discuss the proposed change, the engineer writes up the proposal in a structured format, shares it with the relevant people, and collects written responses over a defined period.
The key discipline here is the defined response window. An RFC that is open indefinitely tends to collect comments forever without reaching a conclusion. A five-day review window with a designated decision-maker who synthesises the feedback and makes a call is far more functional.
Structured Status Updates Instead of Stand-Ups
Daily stand-ups in async teams get replaced with written status updates, typically posted at the start or end of the working day. The format is simple: what was completed yesterday, what is in progress today, and what is blocked. Written versions of this are searchable, available to people in different time zones, and do not require 12 engineers to be on a call at 9:30 am.
The discipline that makes this work is consistency. Teams where people post updates irregularly get less value from the format. Teams where the update is a firm daily expectation find that it becomes a natural part of the workflow within a few weeks.
Synchronous vs Async: Choosing the Right Format
| Situation | Recommended Format | Why |
| Architecture proposal for a new service | Written RFC with comment period | Needs broad input; benefits from structured thinking before discussion |
| Daily progress update | Written async standup | No real-time interaction required; time zone friendly |
| Production incident in progress | Real-time sync plus written incident log | Speed matters; documentation runs parallel |
| Code review feedback | Written inline comments on PR | Async by nature; creates a traceable review record |
| Team member is blocked on a dependency | Direct message with written context first | Reduces back-and-forth; gives recipient full picture before responding |
| Onboarding a new engineer | Documented runbooks plus async Q&A channel | Written material scales; async Q&A preserves answers for future hires |
Build a better async engineering team
Where Async Communication Genuinely Fails
Treating async as a universal solution is as much a mistake as defaulting to meetings for everything. There are situations where real-time communication is the right tool, and forcing async into those contexts creates friction without benefit.
Active Production Incidents
When something is broken and customers are affected, the cost of a delayed response is measured in revenue and trust. Production incidents need real-time coordination. The async discipline here is not to replace the incident call, but to ensure that what happens during and after the incident is documented as it unfolds. The written record then becomes the source for the post-mortem, the runbook update, and the decision log.
Complex Interpersonal or Team Situations
Performance conversations, conflict resolution, and any situation where nuance and emotional tone matter significantly are poorly served by written async communication. The absence of real-time cues makes misunderstandings more likely and repairs harder to make. These situations need synchronous conversation, handled with care.
Early-Stage Brainstorming on Ambiguous Problems
When a problem is genuinely undefined and the team needs to explore a large solution space quickly, a real-time whiteboarding or discussion session can compress hours of async back-and-forth into a single focused conversation. The async discipline here is to document the output of that session in writing immediately after, so the exploration becomes a record rather than a memory.
Building the Documentation Culture That Makes Async Sustainable
The single biggest reason async-first engineering culture fails is not the tooling and it is not the meeting cadence. It is the absence of a documentation culture that makes written communication reliable and valuable. Engineers who have never worked in an environment where documentation was genuinely maintained often experience the shift as extra work with no clear return.
The way to change this is to make documentation pay off quickly and visibly. When a new engineer joins and onboards in three days instead of three weeks because the runbooks are current and the ADRs exist, the team sees the value. When a bug is resolved in two hours because a previous incident was documented thoroughly, the value is concrete. The initial investment in documentation standards pays compounding returns as the team grows and the codebase ages.
Documentation Practices That Support Async Engineering Teams
| Practice | What It Covers | Where It Lives |
| Architecture Decision Records | Technical decisions, options considered, reasoning | Code repository alongside related code |
| Runbooks | Operational procedures, incident response steps | Internal wiki or ops repository |
| RFC documents | Significant proposed changes before implementation | Shared team space with comment threading |
| PR descriptions | What changed, why it changed, how to test it | Version control system pull request body |
| Post-mortem records | Incident timeline, root cause, action items | Incident management tool or team wiki |
Tooling That Supports Async Engineering Teams
The tools are less important than the habits, but certain categories of tooling actively support or undermine async-first culture. Teams that use threaded messaging apps like Slack or Teams benefit from a discipline of writing in threads rather than loose channel messages, and of using dedicated channels for specific topics rather than letting everything pour into a single general discussion space.
Linear, Notion, and Confluence each serve different documentation needs, and the right choice depends on team size and existing workflows. What matters more than the tool is the expectation that written records are created and that they are accessible to everyone who needs them.
Code review tooling that supports inline comments with threads is essential. Review conversations that are captured in the pull request itself provide a permanent record of why certain implementation choices were made, which is exactly the kind of context that gets lost in verbal discussions.
Making the Shift Without Disrupting Momentum
Engineering teams that try to shift to async communication by removing all meetings immediately tend to create confusion rather than clarity. A more practical approach is to start by auditing the existing meeting calendar and categorising each recurring meeting by whether it requires real-time interaction or whether it serves a purpose that a well-structured written format could serve equally well.
Most teams find that a meaningful proportion of their recurring meetings fall into the category of status updates, information sharing, or brief check-ins that are better served by written formats. Replacing those first creates early wins without disrupting the real-time conversations that genuinely add value.
The shift also requires explicit team agreements about response expectations. Async communication works when people understand that a message sent at 6 pm does not require a response that evening, and when they trust that a response will arrive within a defined window the next working day. Without that trust, engineers either feel compelled to monitor channels outside working hours or feel anxious about leaving messages unanswered. Neither outcome supports the quality of work that async communication is meant to enable.
What Better Code Actually Looks Like in Async Teams
The claim that async teams produce better code deserves to be examined rather than just asserted. The mechanism is not that async communication is magical. It is that the conditions async creates, longer stretches of uninterrupted deep work, a habit of writing down decisions, a codebase where context is documented rather than assumed, directly support the kind of careful thinking that good engineering requires.
Code written in two-hour blocks tends to be more coherent than code written in 20-minute gaps between meetings. Pull requests described thoroughly get reviewed more usefully than those with a one-line description. Systems documented in ADRs get maintained more sensibly than those where tribal knowledge is the only source of architectural context.
The teams that demonstrate this most clearly are those working on complex, long-running systems where the cost of a poorly made decision compounds over years. For engineering organisations building scalable ecommerce platforms or AI-integrated systems, the discipline of async communication and the documentation habits it enforces are not just a quality-of-life improvement. They are a competitive advantage that shows up in delivery speed, system reliability, and the ability to onboard capable engineers without months of knowledge transfer overhead.
Most popular pages
-

Ecommerce Platform Migration: Engineering Checklist Before You Switch
Switching your ecommerce platform is one of the most consequential engineering decisions a team can make. Done well, it unlocks better performance, cleaner architecture,...
-
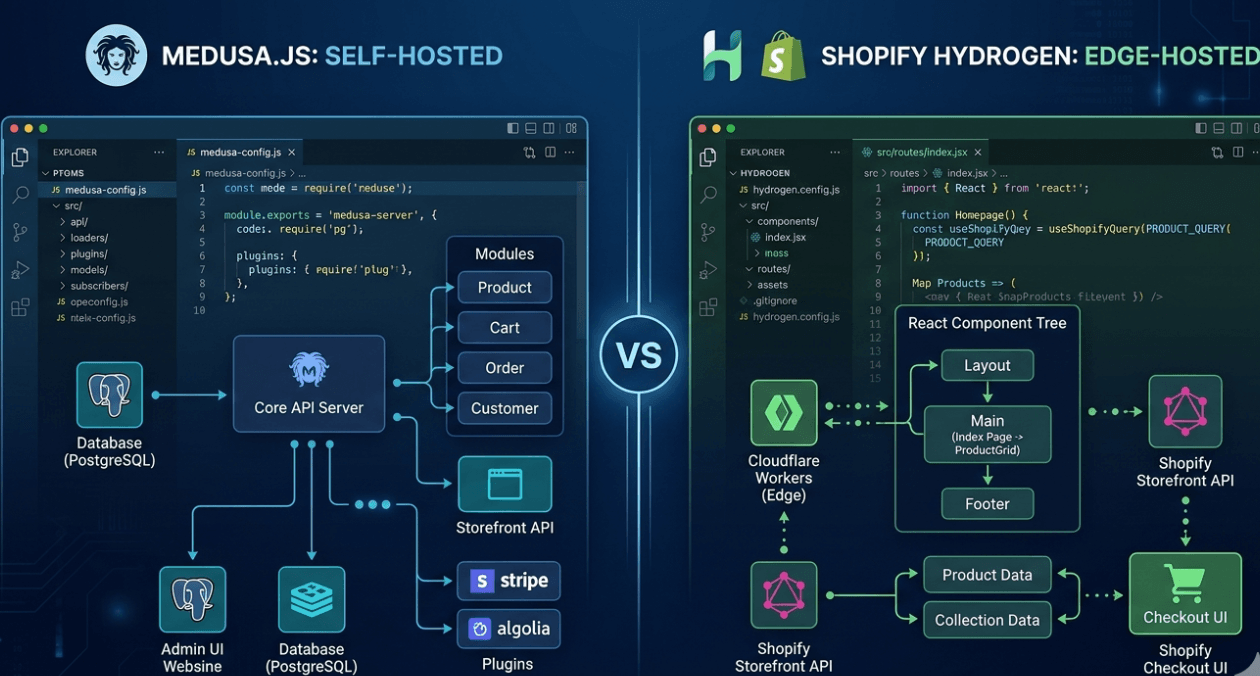
Medusa.js vs Shopify Hydrogen: Which Headless Commerce Stack Should You Build On?
The headless commerce conversation has shifted. Teams are no longer asking whether to go headless. They are asking which stack actually holds up once...
-
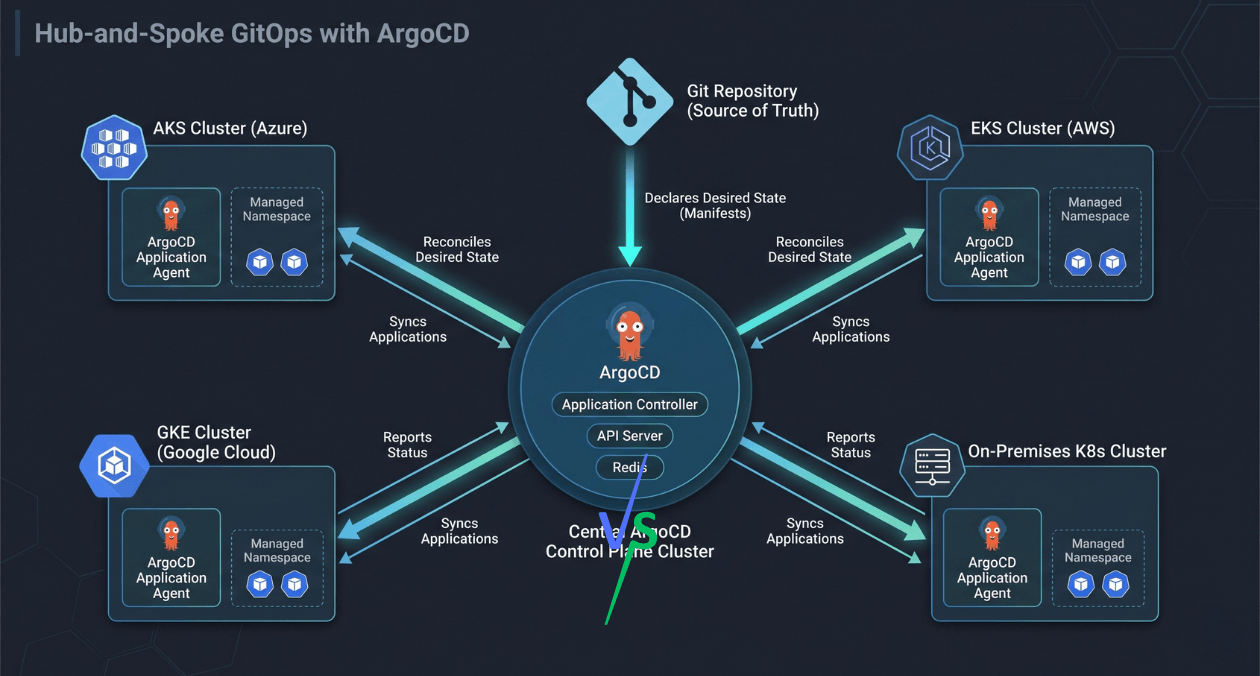
GitOps Beyond ArgoCD: Patterns That Scale for Large Engineering Organisations
ArgoCD became the default answer when someone said "GitOps" for a good few years. It solved the most common problem neatly: sync your Kubernetes...
Ecommerce Platform Migration: Engineering Checklist Before You Switch
Switching your ecommerce platform is one of the most consequential engineering decisions a team can make. Done well, it unlocks better performance, cleaner architecture,...
Medusa.js vs Shopify Hydrogen: Which Headless Commerce Stack Should You Build On?
The headless commerce conversation has shifted. Teams are no longer asking whether to go headless. They are asking which stack actually holds up once...
GitOps Beyond ArgoCD: Patterns That Scale for Large Engineering Organisations
ArgoCD became the default answer when someone said "GitOps" for a good few years. It solved the most common problem neatly: sync your Kubernetes...